RNN without Library (직접구현하는 RNN)
Recurrent Neural Network
보통 Tensorflow, Keras, Pytorch를 사용하게 되면 이미 다른 유저들에 의해서 만들어져 있는 Layer를 불러와서 사용하게 됩니다.
실질적으로 Keras의 경우에는 1~2줄이면 RNN Layer를 구성할수 있습니다.
해당 notebook에서는 직접 RNN을 모두 구현해보았습니다.
RNN은 기존 일반적인 neural network와 달리 input으로만 받는것이 아니라, 이전 시간 포인트의 hidden units 을 tensor로 받습니다.
hidden units을 계산하는 공식은 다음과 같습니다.
hidden units을 구하게 되면은 최종적인 output을 계산할수 있습니다.
\[y^{(t)} = \phi_y \left( \mathbf{B}_{hy} \mathbf{h}^{(t)} + \mathbf{b}_y \right)\]- \(\phi\) : tanh acivation
Data
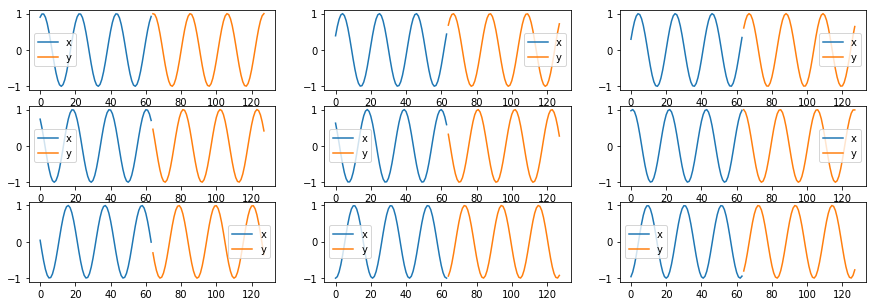
데이터는 Sin 그래프입니다.
x 데이터를 input으로 받아서 y 데이터를 예측합니다.
synced recurrent neural network 를 구현하기 때문에 예측의 초기부분이 잘 안맞는 현상이 일어날것입니다.
해당 현상을 없애는 방법은 delayed recurrent neural network를 구현하거나, 간단하게 Bi-direction으로 해결할 수 있습니다.
해당 문서에서는 가장 간단한 RNN을 구현하기 때문에 해당 이슈는 인지하고 그냥 넘어가겠습니다.
Tensorflow Session Initialization
Tensorflow의 session을 생성합니다.
이때 GPU의 사용량을 제한하는 옵션을 넣습니다.
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.1, allow_growth=True)
sess = tf.InteractiveSession(config=tf.ConfigProto(gpu_options=gpu_options,
log_device_placement=True))RNN Model
X_TIME_SIZE = 64
Y_TIME_SIZE = 64
FEATURE_SIZE = 1
HIDDEN_SIZE = 32
RNN_OUTPUT_SIZE = 32
np.random.seed(0)
rnn_input = tf.placeholder(tf.float64, shape=(None, X_TIME_SIZE, FEATURE_SIZE))
rnn_output = tf.placeholder(tf.float64, shape=(None, X_TIME_SIZE, FEATURE_SIZE))
init_state = tf.placeholder(tf.float64, shape=(None, HIDDEN_SIZE))
# Simple RNN
Wxh = tf.get_variable('Wxh', shape=(FEATURE_SIZE, HIDDEN_SIZE),
initializer=tf.contrib.layers.xavier_initializer(), dtype=tf.float64)
Whh = tf.get_variable('Whh', shape=(HIDDEN_SIZE, HIDDEN_SIZE),
initializer=tf.contrib.layers.xavier_initializer(), dtype=tf.float64)
Wh = tf.concat([Wxh, Whh], axis=0)
Why = tf.get_variable('Why', shape=(HIDDEN_SIZE, RNN_OUTPUT_SIZE),
initializer=tf.contrib.layers.xavier_initializer(), dtype=tf.float64)
bh = tf.get_variable('bh', shape=(1, HIDDEN_SIZE),
initializer=tf.contrib.layers.xavier_initializer(), dtype=tf.float64)
by = tf.get_variable('by', shape=(FEATURE_SIZE, 1),
initializer=tf.contrib.layers.xavier_initializer(), dtype=tf.float64)
# Output layer
linear_w = tf.get_variable('linear_w', shape=(RNN_OUTPUT_SIZE, FEATURE_SIZE),
initializer=tf.contrib.layers.xavier_initializer(), dtype=tf.float64)
linear_b = tf.get_variable('linear_b', shape=(FEATURE_SIZE),
initializer=tf.contrib.layers.xavier_initializer(), dtype=tf.float64)
y_preds = list()
losses = list()
hiddens = np.zeros(X_TIME_SIZE+1, dtype=np.object)
hiddens[-1] = init_state
unstacked_inputs = tf.unstack(rnn_input, axis=1)
unstacked_outputs = tf.unstack(rnn_output, axis=1)
for t, (input_t, y_true) in enumerate(zip(unstacked_inputs, unstacked_outputs)):
concat_x = tf.concat([input_t, hiddens[t-1]], axis=1)
hidden = tf.tanh(tf.matmul(concat_x, Wh) + bh)
y_pred = tf.matmul(hidden, Why) + by
y_pred = tf.nn.tanh(y_pred)
# Linear
y_pred = tf.matmul(y_pred, linear_w) + linear_b
loss = tf.losses.mean_squared_error(y_true, y_pred)
hiddens[t] = hidden
y_preds.append(y_pred)
losses.append(loss)
total_loss = tf.reduce_mean(losses)
train = tf.train.AdamOptimizer().minimize(total_loss)
sess.run(tf.global_variables_initializer())
# TensorBoard
train_writer = tf.summary.FileWriter('./tfboard-log', sess.graph)Training
for epoch in range(100):
train_x, train_y = shuffle(train_x, train_y)
for sample_x, sample_y in batch_loader(train_x, train_y, batch_size=2048):
state = np.zeros((sample_x.shape[0], HIDDEN_SIZE))
_total_loss, _ = sess.run([total_loss, train],
feed_dict={rnn_input: sample_x,
rnn_output: sample_y,
init_state: state})
print(f'[Epoch:{epoch+1}] loss: {_total_loss:<7.4}', end='\r')
print()Evaluation
N = test_x.shape[0]
idices = np.random.choice(np.arange(N), size=9, replace=False)
result_pred = []
result_true = []
for idx in idices:
sample_x = test_x[idx:idx+1]
sample_y = test_y[idx:idx+1]
state = np.zeros((sample_x.shape[0], HIDDEN_SIZE))
_total_loss, _y_preds = sess.run([total_loss, y_preds],
feed_dict={rnn_input: sample_x,
rnn_output: sample_y,
init_state: state})
_y_preds = np.array(_y_preds).reshape(-1, 1)
result_pred.append(_y_preds)
result_true.append(sample_y.reshape(-1, 1))
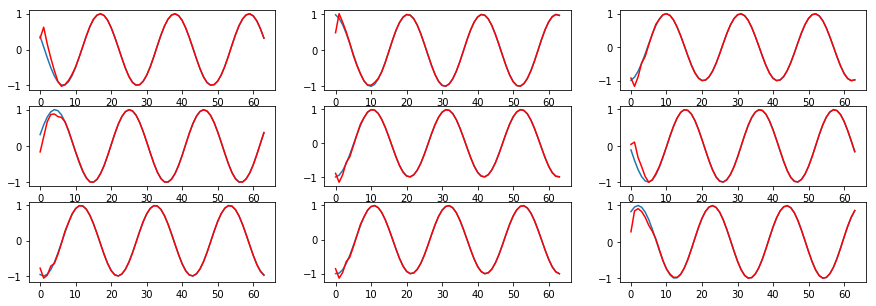
fig, plots = plt.subplots(3, 3)
fig.set_figheight(5)
fig.set_figwidth(15)
plots = plots.reshape(-1)
for i, p in enumerate(plots):
p.plot(result_true[i])
p.plot(result_pred[i], color='red')빨간선은 예측한 부분이고, 파란선은 true 데이터입니다.
파란선이 초기만 보이고 안보이는 이유는 예측이 너무! ㅎ 정확하서 안보이는 것입니다.
초기 부분이 안맞는 이유는 데이터 부분에서 언급하였듯이 sync rnn에서 forecasting 시 일어나는 현상이고,
이는 delayed rnn 또는 bi-direction으로 해결됩니다.