Google BigQuery + Embulk
Table of Contents
Embulkembulk
Installation
Embulk는 git repository에서 코드를 받을 수 있습니다.
설치는 다음과 같이 합니다.
curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"
chmod +x ~/.embulk/bin/embulk
echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcTutorial
embulk example을 이용하면 샘플 CSV가 생성이 되고, 이것을 갖고서 tutorial을 진행할 수 있습니다.embulk guess를 실행하면, embulk는 데이터에 대해서 간단하게 훓어봅니다. 이후 configuration에서 빠진 부분들을추측해서 채워넣게 됩니다. 따라서 사용자는.. 일단 대충 중요한 부분만 적어놓고, 나머지 설정에 들어가야 하는 내용들은 guess가 자동으로 설정해줄수 있습니다.embulk preview를 하게되면 데이터에 대해서 간단하게 확인을 해볼수 있습니다. 또한 설정한 것이 잘 돌아가는지도 확인도 해볼 수 있습니다.embulk run config.yml를 실행하게 되면 설정된 명령되로 embulk는 실제 일을 수행하게 됩니다. 여기서 데이터는 RDBMS에서 가져와서 Google Cloud에 들어갈 수도 있고, 다른 RDBMS또는 S3등.. 다양한 방법으로 데이터를 수정/배포 할 수 있습니다.
embulk example ./try1
embulk guess ./try1/seed.yml -o config.yml
embulk preview config.yml
embulk run config.ymlPlugins
기본적인 embulk에 plugin을 설치해서 postgres, bigquery, mysql, hdfs, oracle, redshift, s3, dynamodb, elasticsearch등등 다양한 저장소에서 데이터를 가져오고나 넣거나 할 수 있습니다. plugin이름은 github의 repository 이름으로 사용하면 되며 자세한 리스트는 여기를 클릭합니다.
설치를 하기 위해서는 embulk gem install <git-repository-name>으로 설치를 합니다.
현재 설치된 plugins의 리스트를 보기위해서는 다음과 같이 합니다.
embulk gem list몇가지 주요 plugin 설치는 다음과 같이 합니다.
보통 input은 데이터를 가져오는 것이고, output은 데이터를 넣습니다.
embulk gem install embulk-input-mysql # MySQL
embulk gem install embulk-input-postgresql # PostgreSQL
embulk gem install embulk-output-bigquery # BigqueryPostgreSQL -> Google BigQuery
PostgreSQL 설정
seed.yml을 먼저 만들어줍니다.
vi seed.yml먼저 PostgreSQL에서 데이터를 가져오는 부분은 다음과 같이 설정을 합니다.
in:
type: postgresql
host: localhost
user: myuser
password: ""
database: MY_DB
schema: public
table: my_table
select: "col1, col2"
out:
type: stddoutvim에서 paste시에 자동으로 indent가 들어가면
:set paste를 해주고, 끝나뒤:set nopaste해줍니다.
데이터가 제대로 가져오는지 확인하기 위해서 preview를 해봅니다.
테이블로 데이터가 출력되면 제대로 데이터를 가져오는 것으로 볼 수 있습니다.
embulk preview seed.ymlGoogle BigQuery 설정
PostgreSQL에서 데이터를 가져온느데 성공했다면, 이제 가져온 데이터를 BigQuery에 넣도록 설정을 하겠습니다.
설정과 관련된 자세한 내용은 링크를 확인합니다.
Create Service Account
먼저 Service Account를 만들어서 API가 사용할 수 있는 계정을 만듭니다.
IAM -> Service accounts 에서 만듭니다.
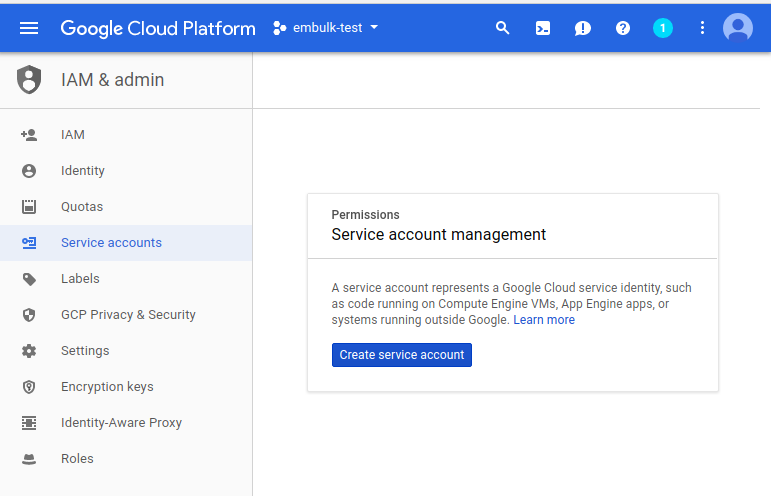
Service account name, Role을 설정합니다.
이때 Role은 BigQuery Admin으로 설정을 하며, 이유는 기존에 없는 테이블을 생성하기위한 권한이 BigQuery Admin입니다.
이하의 권한을 갖게 되면, 기존의 테이블을 수정, 읽기, 쓰기는 가능하지만, 없는 테이블 생성에 대한 권한은 없습니다.
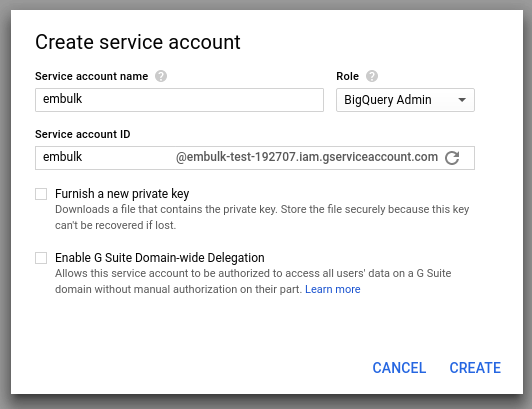
Create Key를 눌러서 Key ID를 만듭니다.
JSON파일 또는 P12를 사용해서 만들수 있으며, 구글에서는 JSON을 추천하고, P12는 호환성때문에 지원하는 듯 합니다.
만들어진후 Service Account ID가 중요합니다. 나중에 Embulk 설정시 service_account_email 에 넣어야 합니다.
BigQuery 설정하기
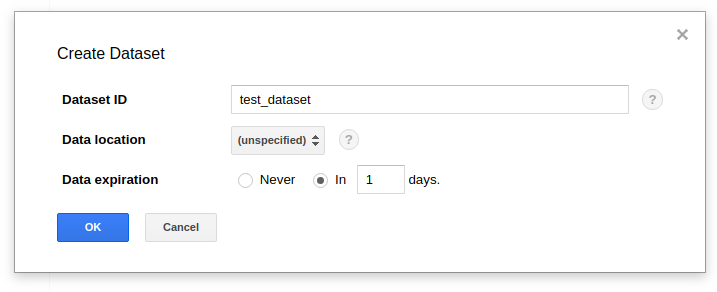
BigQuery -> Create new dataset 을 통해서 dataset을 생성합니다.
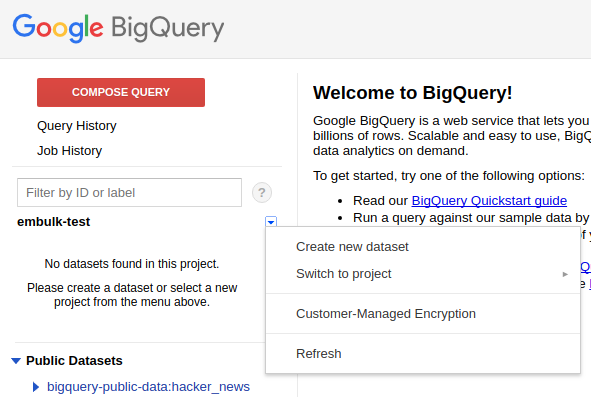
Dataset ID를 설정하고, Location은 US또는 EU인데 설정을 안하면 일반적으로 US가 선택이 됩니다.
Data expiration을 통해서 자동으로 지워지게 할 수 있습니다. 캡쳐화면에서는 하루가 지나면 지워지도록 설정해놨습니다.
seed.yml 수정하기
이제 BigQuery에 데에터를 넣기 위해서 seed.yml을 수정합니다.
in:
type: postgresql
host: localhost
user: myuser
password: ""
database: MY_DB
schema: public
table: my_table
select: "col1, col2"
out:
type: bigquery
mode: append
auth_method: json_key
json_keyfile: /home/anderson/embulk-test-24cf6cb843bf.json
service_account_email: embulk@embulk-test-127806.iam.gserviceaccount.com
dataset: test_dataset
auto_create_table: true
table: embulk_table_%Y_%mEmbulk RUN!
실행하면 PostgreSQL에서 BigQuery로 데이터가 옮겨가게 됩니다.
embulk run seed.yml이후 BigQuery에서 데이터를 확인해 볼 수 있습니다.