Pair Trading - Cointegration and Statistical Arbitrage
1. 결론
- 통계적 차익 거래는 개인이 할 수 없음
- 공개하지는 않지만 차익거래시 효과적인 수익 발생
- 해당글에서 공개된 내용은 개인이 할 수 있는 long position에 대한 결과를 공유.
- 다만 이것도 통계적 차익거래가 아니라면 변수들에 따라서 손실 위험이 발생
- 개인적인 결론은.. short 베팅을 할 수 없는 개인은 하락 위험이 크고, 헤지펀드는 안정적인 수입이 가능
Zeta Value.. 제 회사 이름입니다.
Multi Factor모델을 만들었으며 다양한 변수들의 관계를 보면서 모델이 사고 팔고를 합니다.
다만 근간이 되는 것은 통계적 차익 거래인데.. 역시.. 하락에 베팅을 할 수 없으니.. 안타깝네요.
물론 손으로 할 수 있지만.. 하루종일 차트 보면서.. 그렇게 거래하고 싶지는 않아서 시작했습니다.
맨날 차트만 보면.. 삶에 의미가 없잖아요.. ㅎㅎ
결론은.. 저희도 의미있는 수익이 가설로는 나오지만.. 하락 베팅이 없이는 좀 리스크가 있는 것 같습니다.
2. Pair Trading
예를 들어 간략하게 설명하겠습니다.
SK Hynix는 국내 반도체 대표 회사 입니다.
미국 마이크론도 SK Hynix와 메우 동일하게 메모리 그리고 낸드 플래시를 주력으로 판매하고 있으며,
이 두 기업의 주가의 흐름은 크게 펀더멘탈이 변하지 않는한.. 거의 동일하게 흘러갑니다.
이렇게 아주 비슷한 두 기업을 놓고 봤을때. 두 기업의 주가가.. 동일하게 흘러간다면..
어느순간.. 시장의 비효율성이 생겨 두 기업의 주가의 갭이 생겼을때! (SK하이닉스는 빠지고.. MU는 오름으로 가정)
이때 다음과 같이 투자를 합니다.
- SK Hynix는 long position으로 베팅 합니다.
- MU는 올랐기 때문에 short position으로 베팅 합니다.
이후 다음과 같은 시나리오가 가능합니다.
- 둘다 오름: SK하이닉스는 이익, MU는 손실이기 때문에 이익도 손실도 없습니다. 그냥 제자리..
- 둘다 하락: SK하이닉스는 손실, MU는 이익입니다. 마찬가지로 이익도 손실도 아무것도 없습니다.
- 평균 회귀: SK하이닉스는 오르고, MU는 떨어집니다. -> 둘다 이익이기 때문에 두군데에서 모두 이익을 얻습니다.
듣고보면 거의 무적처럼 들립니다.
하지만 실제 돌려보면.. 통계적 가정에서 벗어나 (예를 들어 정규분포로 가정하였는데.. 그 이상으로 오르거나 빠졌을때.. ) 당연히 손실이 납니다.
포인트는.. 대부분의 경우 이론적으로 차익 거래는.. 헷지펀드에게 날개를 달아주는 것 같습니다.
개인은.. long position밖에 못하기 때문에… 여기서 뛰어난 감각이 없다면.. 힘들어 질 수 있습니다.
3. 데이터
3.1 불러오기
아래코드는 ZetaValue 내부 코드 입니다.
데이터를 받는건 yfinance를 사용해도 됩니다.
데이터에서 Open, High, Low, Close, Volume은 SK하이닉스 가격입니다.
그리고 Open_, High_, Low_, CLose_, Volume_은 마이크론 가격입니다.
from zeta.csv.day import DayCSVLoader
OHLCV_COLS = ['Open', 'High', 'Low', 'Close', 'Volume']
loader = DayCSVLoader()
df = pd.concat([loader.read_csv('000660')[OHLCV_COLS],
loader.read_csv('MU')[OHLCV_COLS]], axis=1)
df.columns = ['Open', 'High', 'Low', 'Close', 'Volume', 'Open_', 'High_', 'Low_', 'Close_', 'Volume_']
df.fillna(method='ffill', inplace=True)
df.dropna(inplace=True)
df = df[df.index > datetime(2015, 1, 1)].copy()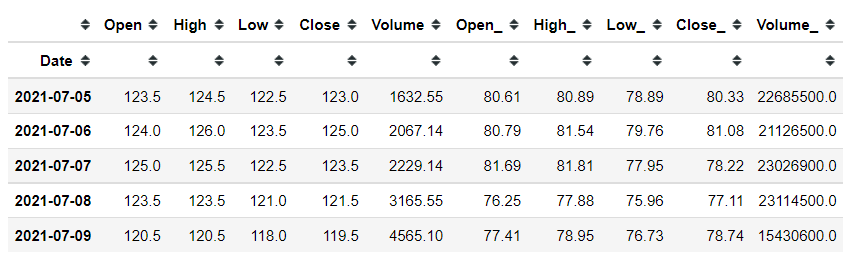
3.2 Price Normalization
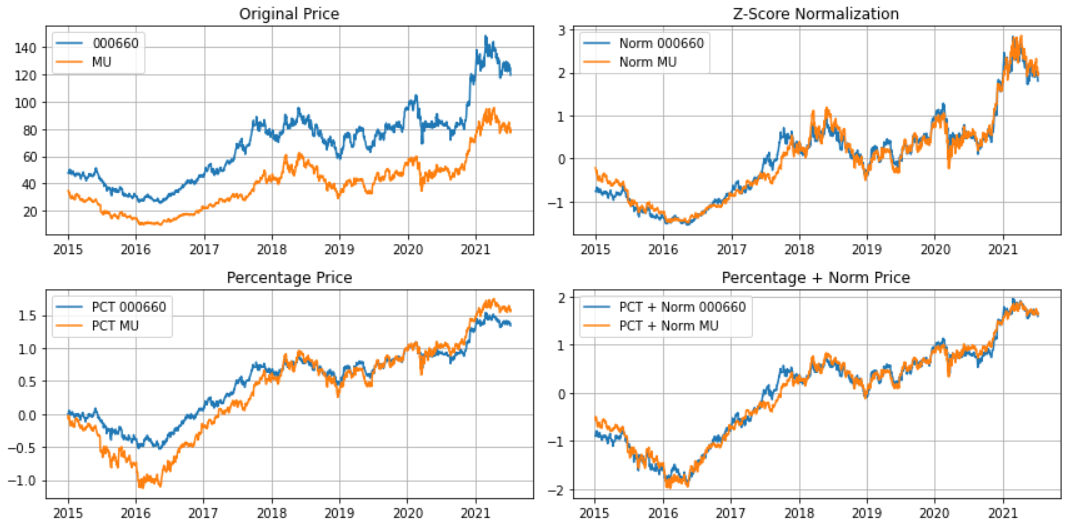
가격 정규화 방법에는 여러가지 방식이 있습니다.
일단 이것을 하는 이유는.. 원화, 달러, 엔화 등등 각각의 가격의 움직임이 다르기 때문에 이것을 맞추는 작업이 큽니다.
일반적인 가격
# Price
price1 = df['Close'] # .pct_change().cumsum().iloc[1:]
price2 = df['Close_'] # .pct_change().cumsum().iloc[1:]
price1.name = '000660'
price2.name = 'MU'Z-Score Normalization
주가가 정규분포를 따른다고 가정합니다. 실제로는 정규분포아님..
# Z-Score Normalization (주가가 정규분포를 따른다고 가정함.. 사실 틀림 -> 잘못 쓰면 손실 크게 남)
norm_price1 = (price1 - price1.mean()) / price1.std()
norm_price2 = (price2 - price2.mean()) / price2.std()Percentage Change
주가를 가격으로 가져가는게 아니라.. 오르고 내름의 percentage로 만듭니다.
서로 다른 가격을 비교시.. percentage로 바꾸면 동일한 단위로 사용 가능해져서 좋습니다.
# Percent Price
pct_price1 = price1.pct_change().cumsum().iloc[1:]
pct_price2 = price2.pct_change().cumsum().iloc[1:]Percentage + Z-Score 둘다 사용
두개의 장점으로 모두 취합니다.
# Percent Price + Z-Score Normalization
pct_norm_price1 = price1.pct_change().cumsum().iloc[1:]
pct_norm_price2 = price2.pct_change().cumsum().iloc[1:]
pct_norm_price1 = (pct_norm_price1 - pct_norm_price1.mean()) / pct_norm_price1.std()
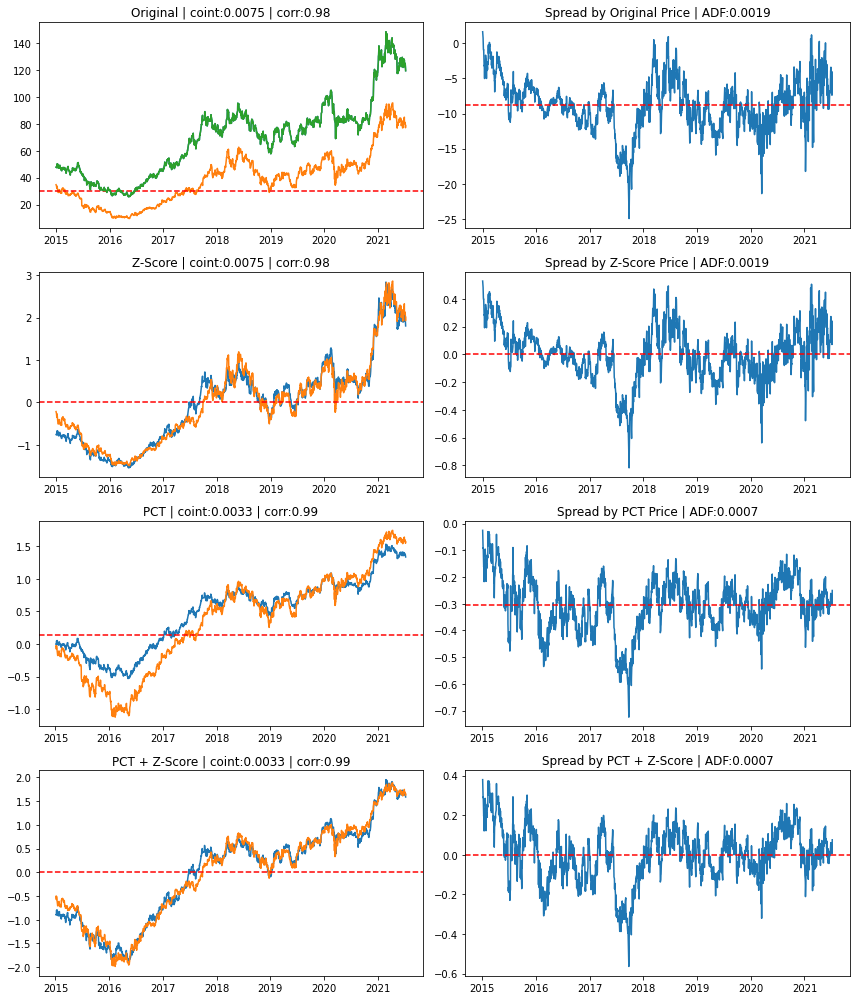
pct_norm_price2 = (pct_norm_price2 - pct_norm_price2.mean()) / pct_norm_price2.std()아래 차트를 보면..Z-Score normalization 그리고 percentage + Z-Score normalization 둘다.. 좋은거 같습니다.
좋은 기준은 두개의 주가가.. 잘 붙어서 흘러 갑니다.
4. Cointegration
Cointegration은 Correlation과 비교하여 좀 더 loose하게 잡아내는 경향이 있습니다.
완벽하게 일치하는 것을 잡아내는게 아니라, Pair Trading처럼 시장의 비효율성이나,
같은 산업군속에서 두 종목의 격차가 벌어졌을때 베팅하는 알고리즘에서 유용하게 사용될 수 있습니다.
직관적인 cointegration의 설명은 아래 그래프와 같이 평균값에서 일정하게 움직이는 모습을 볼 수 있습니다.
정확하게 cointegration 관계를 통계적으로 찾으려면 statsmodels의 coint 함수를 사용하며,
P-value 값이 0.05이하면 됩니다.
4.1 Calculating Cointegration
from statsmodels.tsa.stattools import coint
stat, p_value, _ = coint(price1, price2)
corr = price1.corr(price2)
print(f'Cointegration Stat : {stat:>8.4f}')
print(f'Cointegration P-Value : {p_value:>8.4f}')
print(f'Correlation : {corr:>8.4f}')4.2 Correlation VS Cointegration
Correlation 그리고 cointegration모두 비슷하지만,
cointegration의 경우 평균값에서 분포를 갖는지를 찾고,
correlation의 경우 주로 방향이 같은지를 찾습니다.
x = pd.Series(np.random.normal(1, 1, 100).cumsum())
y = pd.Series(np.random.normal(2, 1, 100).cumsum())
k = pd.Series(np.random.normal(0, 1, 100)) + 20
l = k.copy()
l[0:10] = 30
l[10:20] = 10
l[20:30] = 30
l[30:40] = 10
l[40:50] = 30
l[50:60] = 10
l[60:70] = 30
l[70:80] = 10
l[80:90] = 30
l[90:100] = 10
corr1 = x.corr(y)
_, coint1, _ = coint(x, y)
corr2 = k.corr(l)
_, coint2, _ = coint(k, l)
# Visualization
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
ax[0].plot(x)
ax[0].plot(y)
ax[0].set_title(f'Corr:{corr1:.2f} | Coint:{1-coint1:.2f}')
ax[1].plot(k)
ax[1].plot(l)
ax[1].set_title(f'Corr:{corr2:.2f} | Coint:{1-coint2:.2f}')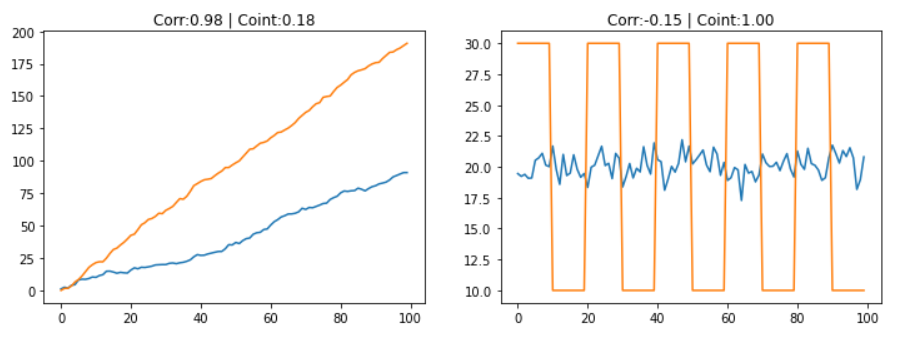
4.3 Order of Integration, I(d)
시계열이 covariance stationary 상태가 되기 위한 최소 차분(difference)의 수를 order of integration 이라고 합니다.
1차분을 해주었다는 것은 I(1) 와 동일하며, 차분하지 않아도 시계열 데이터가 stationary 라면 I(0) 라고 합니다.
4.4 Cointegration Test (Engle-Granger Two-Step Method)
Cointegration을 테스트 하는 방법중의 하나는 Linear Regression을 사용하는 방법입니다.
일단 Linear Regression의 공식은 다음과 같습니다.
OLS를 통해서 beta (slope) 값을 알아낼수 있습니다.
참고로 만약 beta값을 알고 있다면 Dickey-Fuller Test를 하면 됩니다.
하지만 beta값을 모르고 있기 때문에 OLS로 알아냅니다.
Test아이디어는 다음과 같습니다.
- 두개의 시계열 데이터가 non-stationary이며 I(1) 이라면 (1번 차분을 하면 stationary로 될 수 있음)
- 반드시 해당 x, y에 대한 선형 조합은 반드시 stationary 해야 한다. -> 즉 residual값이 stationary 해야 함
즉 위의 선형 공식을 다음과 같이 바꿔서 잔차를 계산후, -> 해당 잔차가 반드시 stationary 해야 함 (이게 테스트)
\[y - \beta x = \alpha + \epsilon\]즉 여기서 알파값(y-intercept)는 그냥 상수이고.. 잔차값이 stationary 테스트를 통해야 함
참고로..
- pct_change().cumsum() 한 가격을 사용시 잘 안됨 -> 테스트 통과 못함
- pct_change() 사용하지 않고.. Z-Score normalization은 테스트 통과 함
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller
x = sm.add_constant(pct_norm_price1) # exog == x
y = pct_norm_price2 # endog == y
ols = sm.OLS(y, x).fit()
bias = ols.params['const'] # bias=y-intercept
beta = ols.params['000660'] # beta=slope
print(f'bias (y-intercept): {bias:>7.4f}')
print(f'beta (slope) : {beta:>7.4f}')
# Calculate Residual <- residual(spread) 값이 stationary 해야지 x, y는 서로 cointegration하다고 할 수 있음
spread = pct_norm_price2 - beta * pct_norm_price1
spread.name = 'Spread'
# Stationarity Test. p-value값이 0.05 이하라면 residual은 stationary 가능성이 높다
p_value = adfuller(spread)[1]
print(f'AdFuller P-Value : {p_value:.4f}')
# Visualization
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
fig.set_tight_layout(True)
ax[0].plot(price1, label='SK Hynix')
ax[0].plot(price2, label='MU')
ax[0].plot(beta * price1, color='red', label='beta * SK Hynix')
ax[0].legend()
ax[1].plot(spread, label='residual')
ax[1].axhline(spread.mean(), color='red')
ax[1].legend()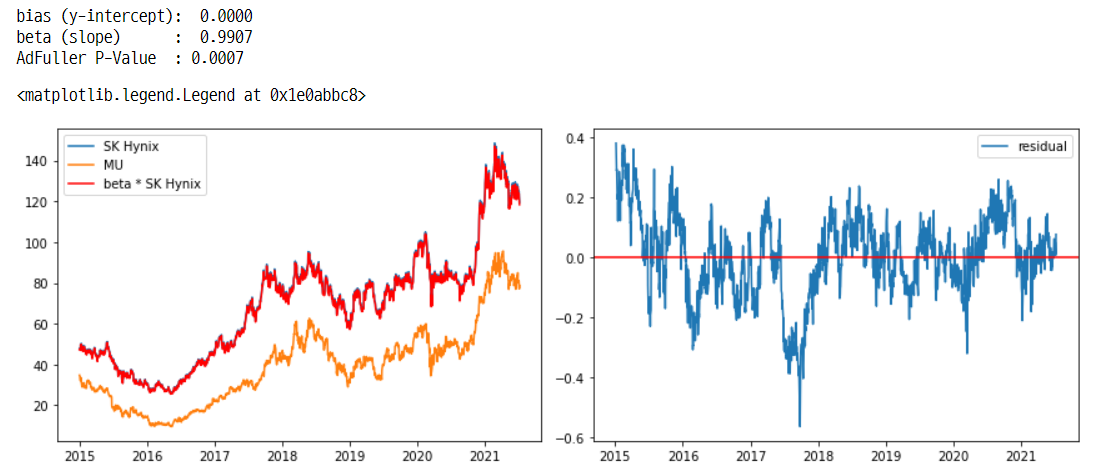
4.5 Normalization에 따른 Cointegration 정리
- 왼쪽차트는 정규화에 따른 가격 그림
- 오른쪽은 Spread
- ADF - Augmented Dickey-Fuller Test
4.6 Calculate Spread!
Spread를 만드는 방법은 여러가지가 있습니다.
저희 회사에서도 기본적인 distance 방식부터, stochastic process 방식부터 ML 까지 많은 연구를 진행했습니다.
여기서는 기본적인 내용만 공유 하겠습니다.
- Eagle-Granger Method
- Ratio Method
Eagle-Granger Method
첫번째로 Eagle-Granger Method는 선형 계수가 stationary인지 체크할때 사용했는데.. 그대로 사용하면 됩니다.
upper 그리고 lower 부분이 선으로 있는데.. 이 선을 넘어갈때마다 베팅을 하는 방식으로 갑니다.
- upper부분으로 넘어가면 SK Hynix에 long position 그리고 MU에는 short position을 갑니다.
- lower부분을 넘기면 그 반대로 합니다.
# Eagle-Granger Method
x = sm.add_constant(pct_norm_price1) # exog == x
y = pct_norm_price2 # endog == y
ols = sm.OLS(y, x).fit()
spread = pct_norm_price2 - beta * pct_norm_price1
lower, upper = spread.quantile([0.2, 0.8])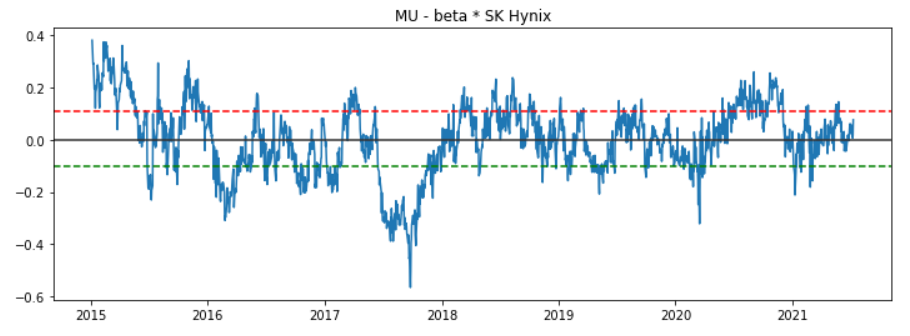
Ratio Method
두번째 방법으로 ratio method 방법인데.. SK Hynix의 경우.. 중간에.. 급격하게 오르는 부분이 있는데..
이 부분 때문에 그림이 튀는 부분이 생김.. -> 결론은.. 이론적으로는 있지만.. 잘 안됨.
# SK Hynix 데이터가 좀 튀는 부분이 있어서 과거 데이터 삭제 함
x = price1.loc[price1.index > datetime(2018, 1, 1)]
y = price2.loc[price2.index > datetime(2018, 1, 1)]
# Ratio Method
ratio = y / x
lower, upper = ratio.quantile([0.2, 0.8])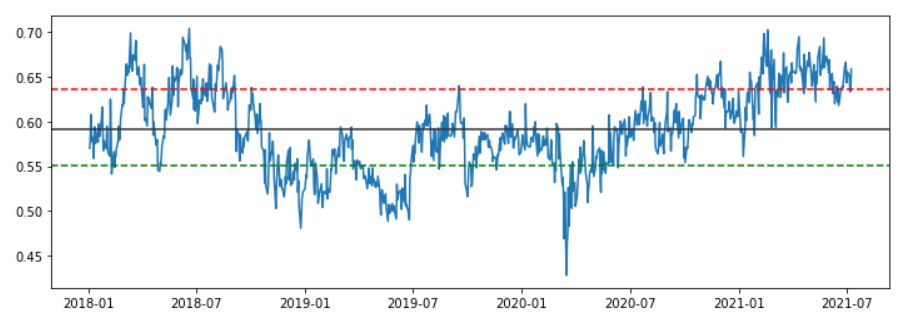
5. Simulation
국내에서는 short을 할 수가 없습니다.
따라서 long position으로만 어떻게 결가가 나오는지 공유 합니다.
당연히 헷지가 없기 때문에 손실이 크게 나올수 밖에 없는 구조 입니다.
이런 점에서.. 대형 헤지펀드사가 매우 부럽네요..
근본적으로 이런 pair 형태의 알고리즘은 헷지 없이는 돌릴수 없습니다.
5.1 Data
stock_df = df[OHLCV_COLS + ['Close_']].dropna().rename(columns={'Close_': 'RefPrice'})
stock_df.tail()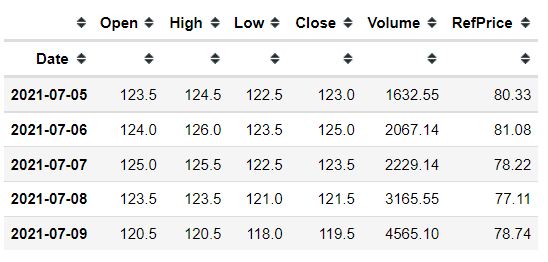
5.2 Indicators
def PCT(arr):
arr = pd.Series(arr)
return arr.pct_change().cumsum().fillna(method='bfill')
def ZScore(arr):
arr = pd.Series(arr)
return (arr - arr.mean()) / arr.std()
def Spread(x, y):
x = ZScore(PCT(x))
y = ZScore(PCT(y))
x_ = sm.add_constant(x) # exog == x
ols = sm.OLS(y, x_).fit()
spread = y - beta * x
spread.name = 'Spread'
return spread
spread = Spread(stock_df['Close'], stock_df['RefPrice'])
lower, upper = spread.quantile([0.3, 0.7])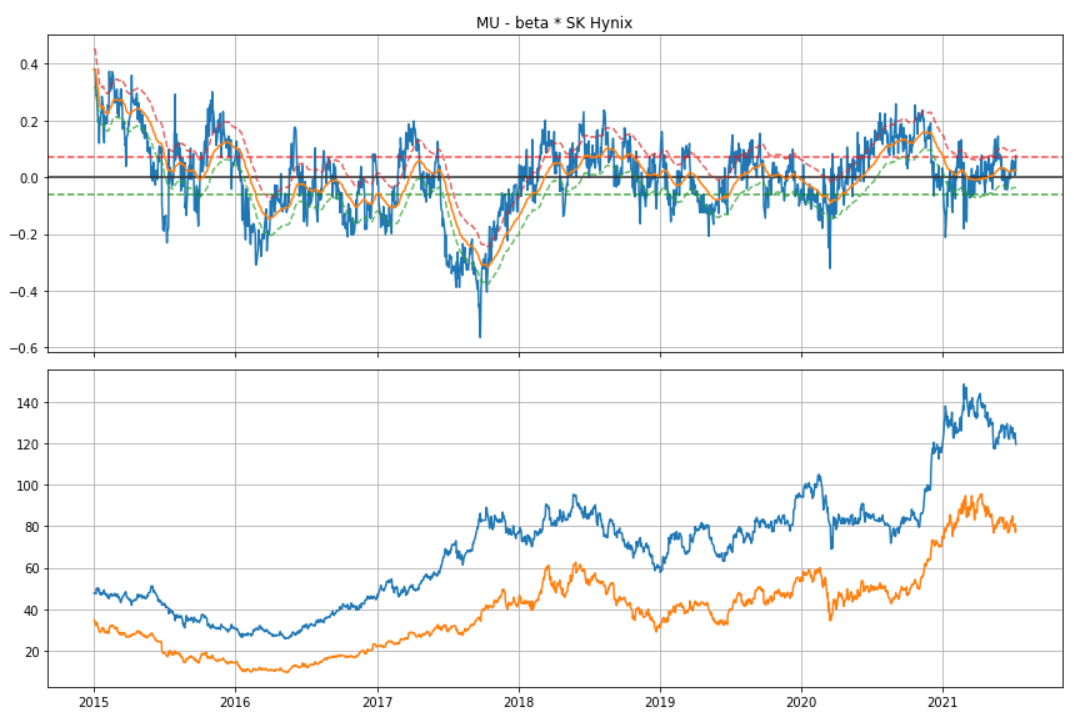
5.3 Pair Trading Backtesting
from backtesting import Backtest, Strategy
class PairStrategy(Strategy):
mean = 0.2
upper = -0.1
lower = -0.05
def init(self):
price1 = self.data.Close # 전날 종가
price2 = self.data.RefPrice # 금일 미국장 종가
# 전일종가 - 미국종가
self.spread = self.I(Spread, price1, price2, name='Spread')
def next(self):
price1 = self.data.Close[-1]
price2 = self.data.RefPrice[-1]
spread = self.spread
if spread[-2] <= self.upper and spread[-1] >= self.upper:
order = self.buy(size=0.8, limit=price1)
elif self.spread[-2] >= self.mean and self.spread[-1] <= self.mean:
self.position.close()
bt = Backtest(stock_df,
PairStrategy,
cash=100000,
commission=0.0036,
exclusive_orders=True)
result = bt.run()
fig = bt.plot(show_legend=False)
display(result)
display(result._trades)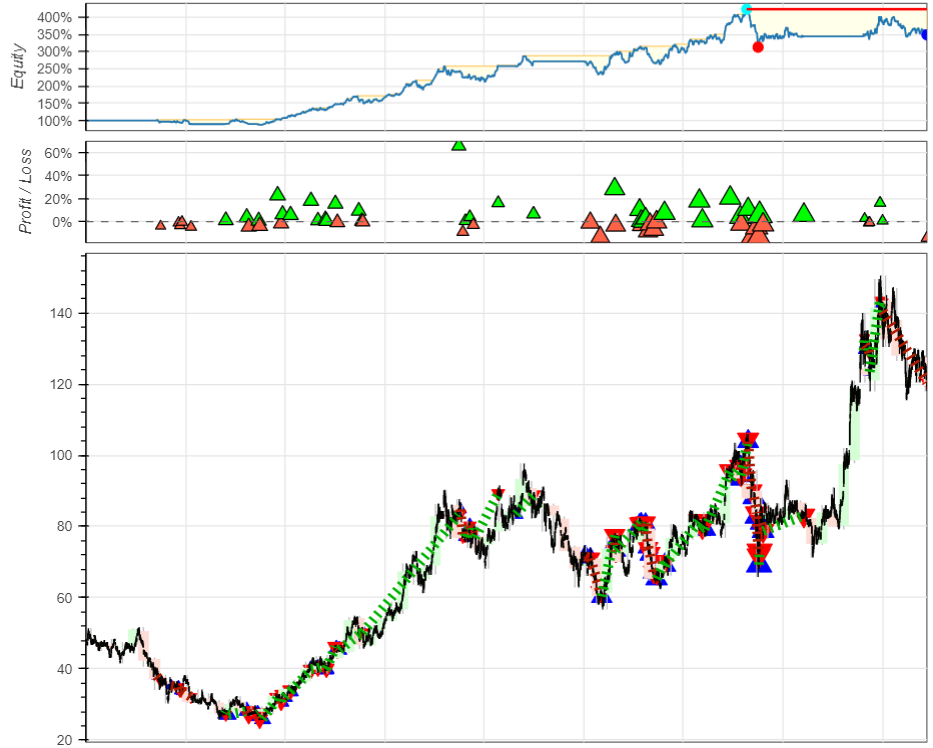
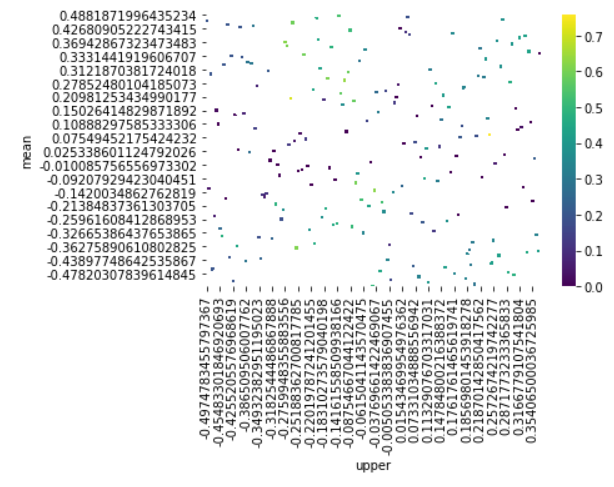
5.4 Optimization
import seaborn as sns
stats, heatmap, optimize_result = bt.optimize(mean=np.arange(-0.5, 0.5, 0.01),
upper=np.arange(-0.5, 0.5, 0.01),
lower=np.arange(-0.5, 0.5, 0.01),
maximize='Sharpe Ratio',
max_tries=200,
random_state=0,
method='skopt',
return_heatmap=True,
return_optimization=True)
display(heatmap.sort_values(ascending=False).head())
sns.heatmap(heatmap.groupby(['mean', 'upper']).mean().unstack()[::-1],
cmap='viridis')