PySpark for ETL
1. Installation
1. Installing PySpark

다운로드 받고 설치하면 됩니다.
이후 동일한 버젼의 (3.3.2) pyspark 를 설치합니다.
$ pip install pyspark==3.3.2
이후 .bashrc 또는 .bash_profile 등에 spark를 설치한 위치를 설정합니다.
copy & paste 하지말고, 아래 내용을 수정해서 사용합니다.
핵심은 파이썬 뭘 써도 상관없는데 pyspark 버젼은 동일해야 하며, 아래의 환경 설정이 제대로 설정되어 있어야 합니다.
export SPARK_HOME=/home/anderson/app/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.7-src.zip:$PYTHONPATH
export PATH=$SPARK_HOME/bin:$SPARK_HOME/python:$PATH
2. Connection
2.1 Hive Connection (안되는듯 함)
사실 가장 자연스럽게 연결 가능한 것이 Hive입니다. Spark 와 찰떡궁합.
필요한 것은 .enableHiveSupport() 를 하면 되고, 그외 정보는 hive-site.xml 에 설정하면 됩니다.
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName("Python Spark SQL Hive integration example")
.enableHiveSupport()
.getOrCreate())
spark.sql("USE <database>")
spark.sql("SELECT * FROM <table>").show()
hive-site.xml 은 다음과 같이 설정합니다.
2.2 Presto Connection
아래와 같이 JDBC 로 Presto 에 연결하는 방법이 있을수 있습니다.
문제는 Spark에서 지원안하는 Presto Types들이 있는데, ARRAY, MAP, ROW 등이며, 이 경우 데이터를 가져오는데 에러가 날수 있습니다.
또한 실행시 테이블 전체를 가져오는 .option("dbtable", "shcema.table") 방식을 사용하던가 또는 ..
.option("query", sql) 을 사용하는 방법.. 둘중에 하나를 하면 됩니다.
from pyspark.sql import SparkSession
# SparkSession 생성
spark = (SparkSession.builder
.appName("Presto JDBC Example")
.config("spark.jars", "/path/to/presto-jdbc-350.jar")
.getOrCreate())
sql = '''
select user_id, name, age, height from db.users
'''
# Presto 테이블 읽기
df = (spark.read
.format("jdbc")
.option("url", "jdbc:presto://presto-databse-url.com:443/hive")
# .option('query', sql)
.option("dbtable", "your_schema.test_table")
.option("driver", "com.facebook.presto.jdbc.PrestoDriver")
.option("user", "user_id")
.option("password", "password")
.load())
3. Parquet
3.1 Loading & Sampling
- spark.sql.warehouse.dir: hive-warehouse 디렉트로에 실제 database 그리고 테이블이 들어감
- spark.driver.extraJavaOptions -Dderby.system.home: metastore_db 안에 데이터베이스 이름, 테이블등등의 데이터가 들어감
- spark.driver.memory: Driver 메모리 설정
- spark.executor.memory: Executor 메모리 설정
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.master("local[*]")
.appName("Spark Test")
.config("spark.ui.port", "4050")
.config('spark.driver.memory', '4G')
.config('spark.executor.memory', '16G')
.config('spark.sql.warehouse.dir', '/Users/anderson/hive-warehouse')
.config('spark.driver.extraJavaOptions', '-Dderby.system.home=/Users/anderson/metastore_db')
.enableHiveSupport()
.getOrCreate()
)
spark.sql('show databases').toPandas()
spark.sql('use anderson_db')
spark.sql('select current_database()').toPandas()
읽기
data = spark.read.parquet('./data')
print('Data Row Sie:', data.count())
data.sample(0.001).toPandas()
3.2 Temporary View Table
data.createOrReplaceTempView("users")
sql = """
SELECT * FROM users
WHERE salary >= 200000
"""
users = spark.sql(sql)
users.toPandas()
3.3 Create Hive Table
saveAsTable('테이블이름')을 해줘야지 hive-warehouse 에 실제 데이터가 저장이 됨.save('저장 경로'): 으로 저장하게 되면 그냥 해당 경로로 저장이 되며 hive-warehouse 에 저장이 되는게 아님.
spark.sql("CREATE DATABASE IF NOT EXISTS anderson")
spark.sql("USE anderson")
(
data.write.mode("overwrite")
.partitionBy("country")
.format("parquet")
.saveAsTable("users")
)
spark.sql("select * from anderson.users").sample(0.001).toPandas()
이렇게 생성하면 아래와 같은 구조로 테이블이 생성됩니다.
./spark-warehouse
└── anderson.db
└── users
├── country=%22Bonaire
│ └── part-00000-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
├── country=Afghanistan
│ ├── part-00000-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
│ ├── part-00001-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
│ ├── part-00002-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
│ ├── part-00003-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
│ └── part-00004-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
├── country=Aland Islands
│ └── part-00000-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
├── country=Albania
│ ├── part-00000-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
│ ├── part-00001-82e73039-7913-48a0-beef-c2317978be87.c000.snappy.parquet
3.4 Save as parquet files
(
data.write.mode("overwrite")
.partitionBy("country")
.format("parquet")
.save("users")
)
아래와 같은 형식으로 생성됩니다.
./users
├── country=%22Bonaire
│ └── part-00000-31286881-2130-4a6f-9183-d6e8eeaa1c77.c000.snappy.parquet
├── country=Afghanistan
│ ├── part-00000-31286881-2130-4a6f-9183-d6e8eeaa1c77.c000.snappy.parquet
│ ├── part-00001-31286881-2130-4a6f-9183-d6e8eeaa1c77.c000.snappy.parquet
│ ├── part-00002-31286881-2130-4a6f-9183-d6e8eeaa1c77.c000.snappy.parquet
│ ├── part-00003-31286881-2130-4a6f-9183-d6e8eeaa1c77.c000.snappy.parquet
│ └── part-00004-31286881-2130-4a6f-9183-d6e8eeaa1c77.c000.snappy.parquet
├── country=Aland Islands
│ └── part-00000-31286881-2130-4a6f-9183-d6e8eeaa1c77.c000.snappy.parquet
4. CSV to Parquet
4.1 Default Initialization
from matplotlib import pylab as plt
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.master("local[*]")
.appName("Sales")
.config("spark.ui.port", "4050")
# .enableHiveSupport()
.getOrCreate()
)
4.2 Read CSV
from pyspark.sql import types as t
data = (
spark.read.option("inferSchema", True)
.option("delimiter", ",")
.option("header", True)
.csv("vgsales.csv")
)
# type casting
data = data.withColumn("Year", data.Year.cast(t.IntegerType()))
# Set Temporary Table
data.createOrReplaceTempView("sales")
print("n rows:", data.count())
data.show(3)
data.limit(3).toPandas()
4.3 Missing Values
from pyspark.sql import functions as F
def display_missing_count(df):
missing_df = df.select(
[
F.count(F.when(F.isnan(c) | F.col(c).isNull(), c)).alias(c)
for c in df.columns
]
).toPandas()
display(missing_df)
display_missing_count(data)

아래는 missing values 를 제거 합니다.
from functools import reduce
def filter_missing_values(df):
return df.where(
reduce(
lambda a, b: a & b,
[~F.isnan(col) & F.col(col).isNotNull() for col in df.columns],
)
)
data = filter_missing_values(data)
display_missing_count(data)
4.4 GroupBy
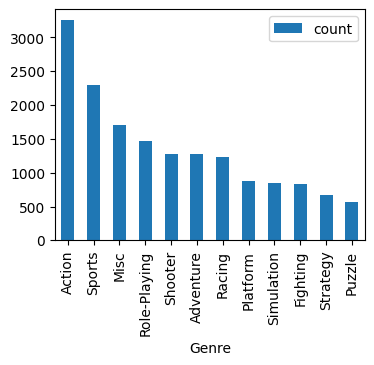
fig, ax = plt.subplots(1, figsize=(4, 3))
(
data.groupBy("Genre")
.count()
.orderBy(F.col("count").desc())
.toPandas()
.plot(x="Genre", y="count", kind="bar", ax=ax)
)
4.5 SQL Query
query = """
SELECT *
FROM (SELECT *,
RANK(Global_Sales) OVER (PARTITION BY Year ORDER BY Global_Sales) as rank_sales
FROM sales) t
WHERE t.rank_sales = 1
ORDER BY Year
"""
df = spark.sql(query).toPandas()
4.6 Write to Parquet
sales.parquet 디렉토리가 생성됩니다.
# mode: overwrite, append (새로운 파일이 만들어짐)
data.write.mode("overwrite").parquet("sales.parquet")
└── 01 CSV to Parquet.ipynb
├── part-00000-3712a917-89eb-4b60-93f3-9f3973cabb0b-c000.snappy.parquet
└── _SUCCESS