EMR & SPARK
1. Installation
1.1 Install Dependencies
$ pip install pyspark[all]
$ sudo apt-get install openjdk-8-jdk
$ java -version
1.2 Install Hadoop
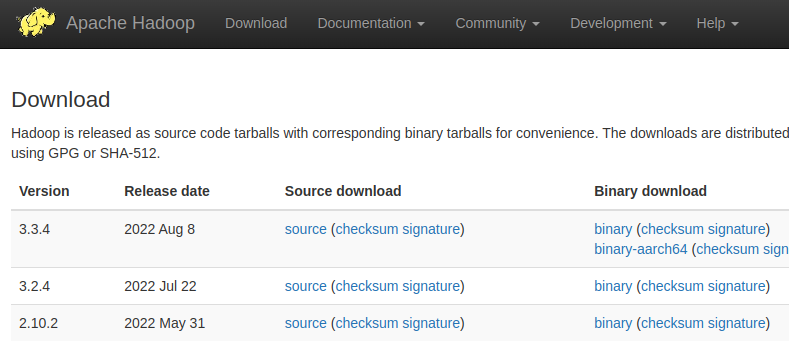
하둡 다운로드 페이지에 접속해서 하둡 바이너리를 다운로드 받습니다.
binary download 에서 최신버젼의 binary를 눌러서 다운로드 받습니다.
$ tar -xvf hadoop-3.3.4.tar.gz
$ mkdir -p ~/app
$ mv hadoop-3.3.4 ~/app/
$ ln -s ~/app/hadoop-3.3.4/ ~/app/hadoop
~/.bashrc 에 다음을 추가 합니다.
정확한 위치는 수정이 필요합니다.
# Java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
# Hadoop
export HADOOP_HOME=$HOME/app/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
설치확인은 터미널 종료후 다시 키고 다음을 실행시킴니다.
$ hadoop version
Hadoop 3.3.4
1.3 AWS Preparation
- EC2 KeyPair 를 미리 만들어놔야 합니다.
aws sts get-caller-identity사용해서 접속이 잘 되는지도 확인합니다.
1.4 S3 Bucket
S3 Bucket을 생성합니다.
Amazon EMR은 S3를 사용해서 데이터를 저장하고, 연산을 합니다.
- Bucket Name:
data-emr-tutorial - Region:
ap-northeast-2 - ACL: ACL 비활성화됨(권장)
1.5 Bootstrap (EMR-6.7.0 기준)
클러스터안의 모든 노드들이 동일한 패키지를 갖을 수 있도록 하기 위해서 bootstrap 파일을 만들어 줍니다.
emr_bootstrap.sh
가장 중요한 부분이 pip 버젼의 사용인데, sudo pip 사용시 에러가 납니다. (sudo pip3 는 가능)
pip부분에서 에러가 난다면.. 일단 comment out 시키고 EC2가 생성되면.. 직접 들어가서 pip어떻게 사용되는지 확인하면 됩니다.
또한 S3에 남겨지는 에러 메세지를 보면서 문제를 해결하는게 중요합니다.
특히 spark관련해서 특정 버젼의 pyspark 설치가 필요 할 수 있습니다.
EMR 버젼에 따라서 pip-3.4 또는 pip-3.6 등등 모두 다른 버젼을 갖고 있습니다.
문제는 특정 버젼을 정의시 업그레이드 또는 해당 버젼에서 지원하는 pip 버젼을 알고 있어야 함으로 좋은 방향은 아닙니다.
따라서 pip2 또는 pip3 같은 방식으로 사용하는게 좋습니다.
또한 set -x -e 를 사용했는데, 이는 추후 디버깅시에 어떤 명령어를 사용했는지를 로깅시에 파악하기 좋습니다.
해당 명령어가 없다면 출력된 output만 있고, 어떤 명령어가 사용됐는지 안 보입니다.
#!/bin/bash
set -x -e
# update and install some useful yum packages
sudo yum install -y jq
# Install Python packages
aws s3 cp s3://data-emr-tutorial/bootstrap/requirements.txt ./
sudo pip3 install -U --upgrade pip
pip3 install -U -r requirements.txt
requirements.txt
pyspark==2.3.4 같은 정확한 버젼 설치가 필요하다.
이유는 다른 버젼이라면 sage-maker 와 충돌이 날 수 있는데 에러가 나면.. bootstrap 에서 에러가 나고.. 전체 클러스터가 떨어진다
EMR-6.7.0 기준이다.
pandas
numpy
matplotlib
pyspark==2.3.4
1.6 Upload files
# 복사 / s3:// 반드시 있어야 함
$ aws s3 cp emr_bootstrap.sh s3://data-emr-tutorial/bootstrap/
$ aws s3 cp requirements.txt s3://data-emr-tutorial/bootstrap/
# 확인 / 끝에 slash 꼭 붙여줘야 함 / s3:// 로 시작 안해도 됨
$ aws s3 ls data-emr-tutorial/
1.7 Create a Cluster on EMR
AWS EMR 서비스를 들어온 다음에 Create Cluster를 누르면 다음과 같은 화면이 보입니다.
고급 옵션으로 이동 or Go to advanced options을 누른후..
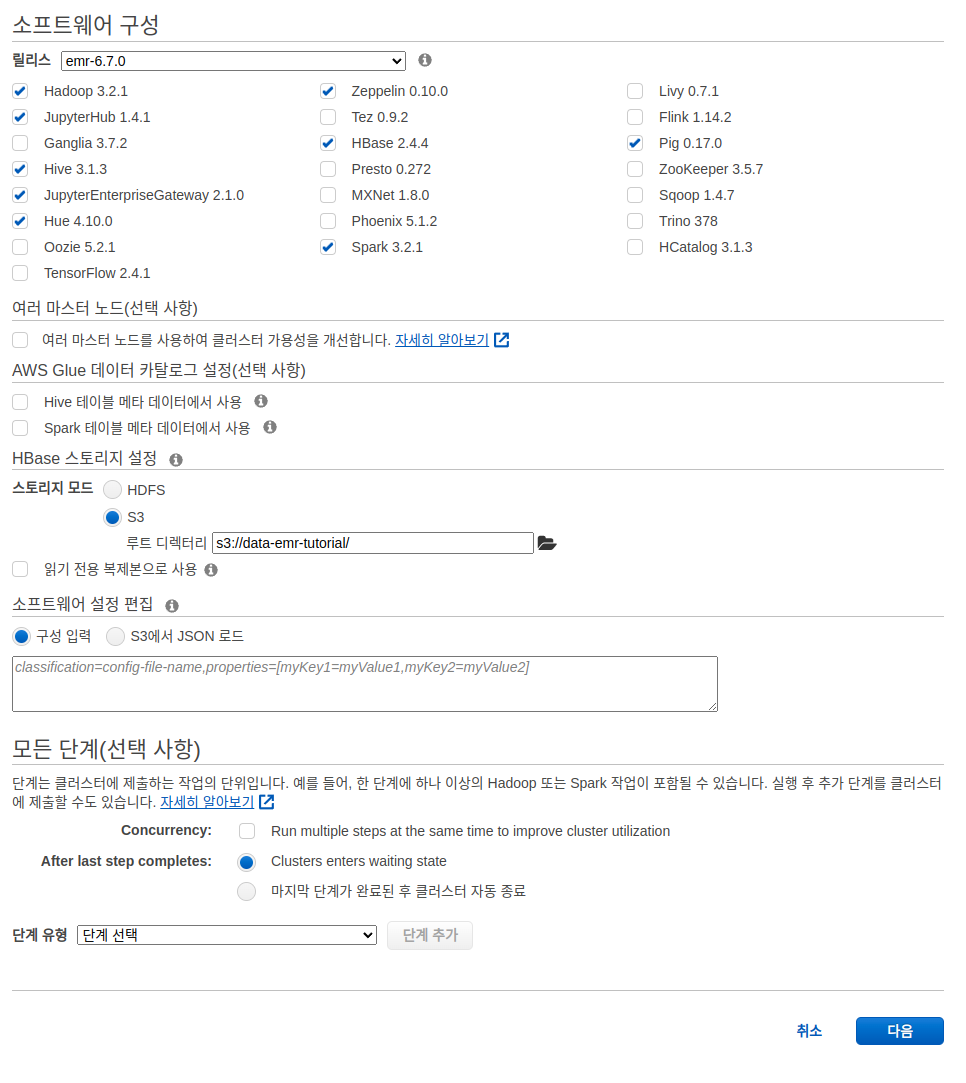
다음이 포함되어 있어야 합니다.
- Hadoop
JupyterHubJupyterEnterpriseGateway- 추후 Notebook 사용시 필요SparkZeppelinHueHBase- Pig
- 그리고 스토리지 모드는 S3 를 사용하며 미리 만들어둔 s3://data-emr-tutorial/ 을 사용합니다.
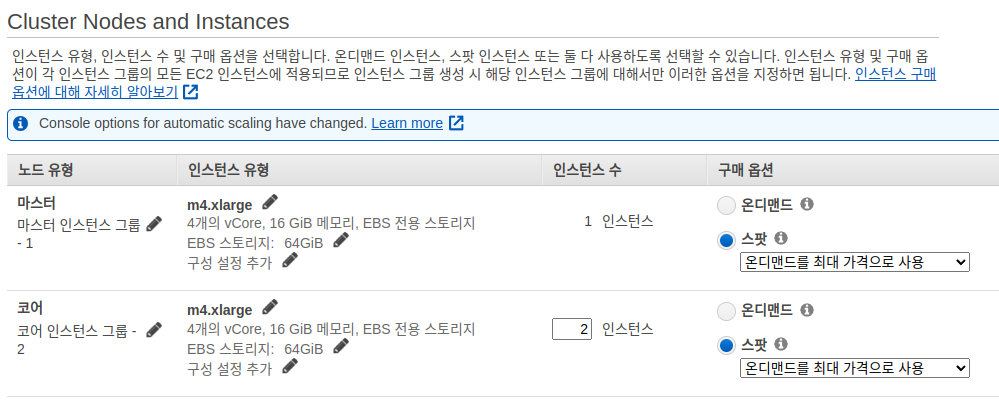
Tutorial 에서는 m4.xlarge 를 사용합니다. (최소 16Gib 메모리가 필요. 그 이하면 클러스터 떨어짐)
또한 100Gb root device EBS volume 을 사용합니다.
기본 10Gb를 사용시 용량문제로 bootstrap error 가 나옵니다.

그리고 부트스트랩 작업에서는 미리 올려둔 emr_bootstrap.sh 를 선택해줍니다.
추가는 부트스트랩 작업 추가에서 사용자 지정 작업 을 선택후 구성 및 추가 를 누르면 됩니다.
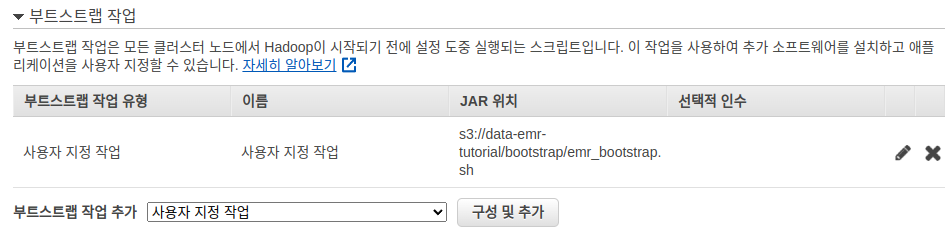
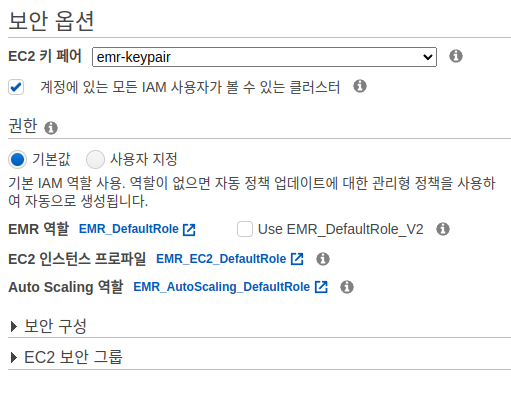
마지막으로 EC2 키 페어를 설정합니다.
확인하기 위해서 다음의 명령어로 Cluster 정보를 찾아봅니다.
Cluster ID 부분에는 j-AZAL77EINX2B 같은 Cluster ID를 넣습니다.
# 실행중인것 보고싶으면 `--cluster-states RUNNING` 으로 하면 됨
$ aws emr list-clusters --cluster-states WAITING | jq -r .Clusters[0].Id
j-AZAL77EINX2B
$ aws emr describe-cluster --cluster-id j-AZAL77EINX2B
2. EMR Steps
일반적으로 spark-submit 을 통해서 마스터 서버로 job을 보내게 되는데,
EMR 에서는 spark-submit이 아니라 aws emr add-steps 를 통해서 job을 실행합니다.
2.1 Mcdonald Data
데이터는 맥도날드 데이터를
사용합니다.
데이터를 로컬 컴퓨터에 다운로드 받습니다.
# 맥도날드 데이터 받기
$ wget https://raw.githubusercontent.com/AndersonJo/code-snippet/master/002-Pyspark/macdonald/mcdonalds_dataset.csv
2.2 Mcdonald Python Code
mcdonald.py
from argparse import Namespace, ArgumentParser
from pyspark.sql import SparkSession
def init() -> Namespace:
parser = ArgumentParser()
parser.add_argument('--source', default='mcdonalds_dataset.csv')
parser.add_argument('--output', default='output.csv')
args = parser.parse_args()
return args
def main():
args = init()
data_source = args.source
data_output = args.output
print('source:', data_source)
print('output:', data_output)
spark = (SparkSession
.builder
.appName('Macdonald Broken Machine')
.config('spark.driver.maxResultSize', '1g')
.getOrCreate())
spark.sparkContext.setLogLevel('WARN')
df = (spark.read
.option('header', 'true')
.csv(data_source))
df.createOrReplaceTempView('df')
query = r'''
select city, is_broken, count(*) as cnt from df
group by city, is_broken
order by 3 DESC
limit 10
'''
result_df = spark.sql(query)
(result_df
.repartition(1) # spark nodes의 갯수에 따라서 여러개의 파일이 만들어지는데, repartition(1)로 하나로 묶을수 있다
.write
.option('header', 'true')
.csv(data_output))
print(result_df.show())
if __name__ == '__main__':
main()
정상 작동하는지 체크하기 위해서 다음을 실행합니다.
$ python mcdonald.py
$ cat output.csv/part-*.csv
city,is_broken,cnt
Houston,False,105
Chicago,False,95
<생략>
2.3 Upload Files to S3
# 업로드
$ EMR_S3=data-emr-tutorial
$ aws s3 cp mcdonalds_dataset.csv s3://${EMR_S3}/data/
$ aws s3 cp mcdonald.py s3://${EMR_S3}/code/
2.3 Run Step
$ EMR_SPARK_CLUSTER_ID=$(aws emr list-clusters --cluster-states WAITING | jq -r .Clusters[0].Id)
$ EMR_SPARK_APP_NAME="My Spark Test"
$ EMR_SPARK_SCRIPT=s3://${EMR_S3}/code/mcdonald.py
$ EMR_SPARK_SOURCE=s3://${EMR_S3}/data/mcdonalds_dataset.csv
$ EMR_SPARK_OUTPUT=s3://${EMR_S3}/data/output.csv
# 기존 output 삭제
$ aws s3 rm --recursive ${EMR_SPARK_OUTPUT}
# EMR Run mcdonald.py
$ aws emr add-steps \
--cluster-id=${EMR_SPARK_CLUSTER_ID} \
--steps Type=Spark,Name="${EMR_SPARK_APP_NAME}",ActionOnFailure=CONTINUE,Args=[${EMR_SPARK_SCRIPT},--source,${EMR_SPARK_SOURCE},--output,${EMR_SPARK_OUTPUT}]
아래와 같은 결과가 나옵니다.
{
"StepIds": [
"s-1B2QJB1RNMP3"
]
}
결과는 AWS Console 에서 보는게 빠릅니다.
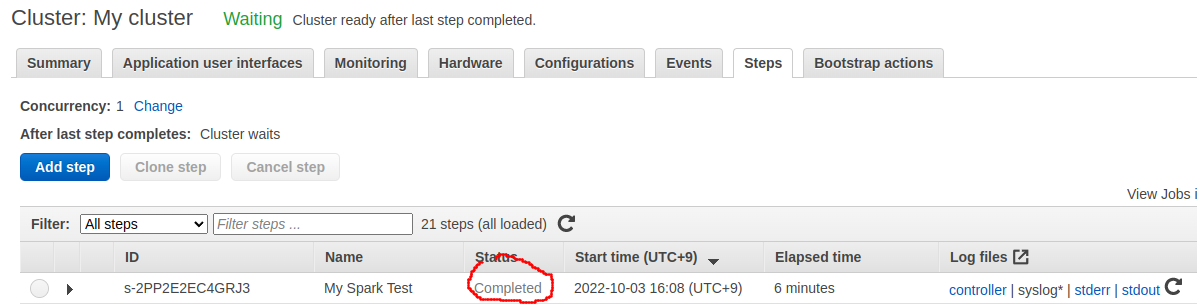
3. PySpark
3.1 Configure Hadoop
먼저 EMR의 마스터 서버의 주소를 알아냅니다.
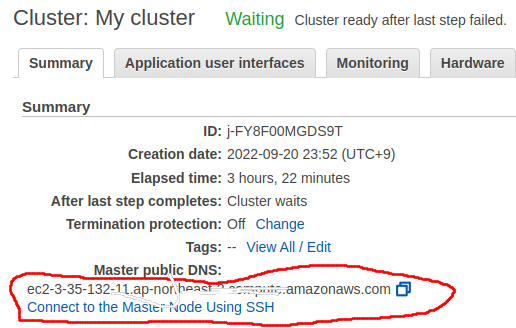
이후 core-site.xml 그리고 yarn-site.xml 에서 주소를 넣어야 합니다.
아래와 같이 수정하되, 위에서 복사한 마스터 주소를 치환해서 넣습니다.
$ cd ~/app/hadoop/etc/hadoop
core-site.xml
hdfs://<마스터 퍼블릭 DNS> 형태로 value 태그에 넣어주면 됩니다.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ec2-3-35-132-11.ap-northeast-2.compute.amazonaws.com</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>ec2-3-35-132-11.ap-northeast-2.compute.amazonaws.com:8032</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ec2-3-35-132-11.ap-northeast-2.compute.amazonaws.com</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hdfsadmingroup</value>
<description>The name of the group of super-users.</description>
</property>
</configuration>
~/.bashrc
# Java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
# Hadoop
export HADOOP_HOME=/home/anderson/app/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:$LD_LIBRARY_PATH
추가적으로 마스터 서버에 들어가서 다음을 해줍니다.
$ sudo usermod -G hdfsadmingroup -a root