AutoML
- Introduction
- Data
- Manual Models
- Auto-Sklearn
- MLBox - {:.} Reading Data - {:.} Optimization - {:.} Prediction
Introduction
Machine learning 그리고 deep learning은 단순히 연구에서 머물지 않고, 실제 서비스 그리고 엔터프라이즈 환경에서 사용이 되고 있습니다.
하나의 모델을 만들고 튜닝하는데에는 ML engineer의 고도화된 튜닝 기법들이 필요합니다.
문제는 튜닝을 하는데 많은 시간이 소요가 되며, 이것은 낮은 생산성으로 이어지게 됩니다.
특히 딥러닝의 경우 정말 많은 hyperparameters 가 존재합니다.
모델의 아키텍쳐, learning rate, epsilon value, drop rate 등등 종속변수에 영향을 미치는 변수들이 상당히 많습니다.
현실적인 관점에서 기존 ML은 그나마 좀 빠르게 학습되는데 반해서, 딥러닝 모델의 경우 모델에 따라서 몇일이 걸리는 일도 발생합니다.
Auto ML은 다음의 3가지의 문제를 해결하는데 도움을 줍니다.
- Time Saving: Auto ML은 data extraction 그리고 algorithm tuning을 자동으로 하면서, 수작업으로 하던 일들을 크게 줄여줍니다.
- Improved Accuracy: 실제 업무를 하다보면, 모델이 나오는 것까지는 하지만 튜닝에 들어가는 시간이 없어서 대충 기본값만 사용하는 케이스가 꽤 많습니다. 이러한 일들이 자동으로 되면서 휴먼 에러를 줄이고, 일정상 못하던 튜닝이 자동으로 되면서 매우 높은 accuracy로 향상 시킬수 있습니다.
Data
Regression Data
먼저 예제로 사용할 regression data를 정의합니다.
예제에서는 diabetes 데이터를 활용합니다.
def regression_data():
np.random.seed(2685)
x_data, y_data = load_diabetes(True)
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data,)
columns = load_diabetes()['feature_names']
return x_train, y_train, x_test, y_test, columns
def visualize_regression(y_true, y_pred):
fig, plots = subplots(1, 2, figsize=(16, 6))
plots = plots.reshape(-1)
sort_idx = np.argsort(y_true)
y_sorted_true = y_true[sort_idx]
y_sorted_pred = y_pred[sort_idx]
sns.scatterplot(np.arange(len(y_pred)), y_pred, label='blue', ax=plots[0])
sns.scatterplot(np.arange(len(y_pred)), y_true, color='red', label='true', ax=plots[0])
sns.scatterplot(np.arange(len(y_pred)), y_sorted_pred, label='blue', ax=plots[1])
sns.scatterplot(np.arange(len(y_pred)), y_sorted_true, color='red', label='true', ax=plots[1])
plots[0].set_title('unsorted predictions')
plots[1].set_title('sorted predictions')
print('RMSE:', mean_squared_error(y_test, y_pred) ** 0.5)
print('R^2 :', r2_score(y_test, y_pred) ** 0.5)Manual Models
Auto ML을 사용안했을때와 비교하기 위해서 제가 손 튜닝한 모델의 performance를 기록합니다.
Decision Tree
from sklearn.tree import DecisionTreeRegressor
x_train, y_train, x_test, y_test, columns = regression_data()
dt = DecisionTreeRegressor()
dt.fit(x_train, y_train)
# Evaluation
y_pred = dt.predict(x_test)
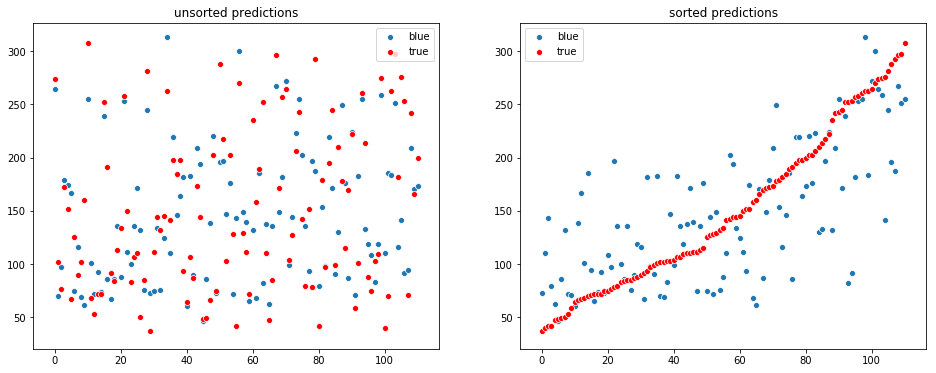
visualize_regression(y_test, y_pred)RMSE: 72.95889253545451
R^2 : 0.25863112218664946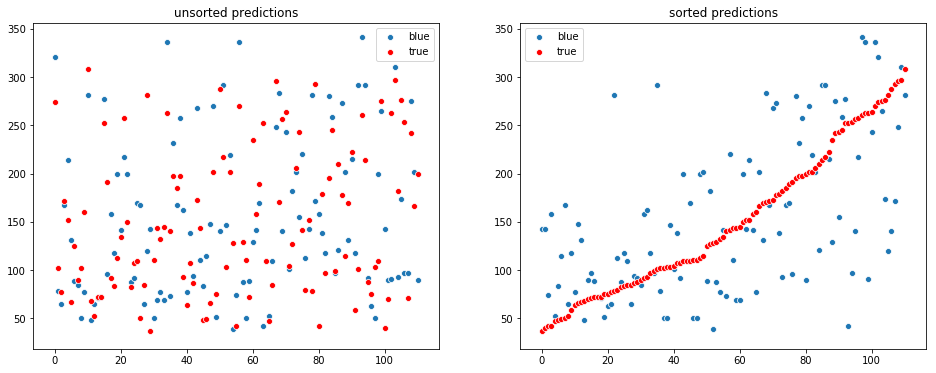
LightGBM
# Data
x_train, y_train, x_test, y_test, columns = regression_data()
# LightGBM Regression Model
gbm = lgb.LGBMRegressor(mc='0,0,0,0,0,0,0,0,0,0',
learning_rate=0.07,
n_estimators=64,
seed=0)
gbm.fit(x_train, y_train, eval_metric='l2',
eval_set=[(x_test, y_test)],
early_stopping_rounds=5, verbose=False)
# Evaluation
print('Best Iteration:', gbm.best_iteration_)
y_pred = gbm.predict(x_test, num_iteration=gbm.best_iteration_)
visualize_regression(y_test, y_pred)Best Iteration: 33
RMSE: 52.06965531596246
R^2 : 0.7243784507478606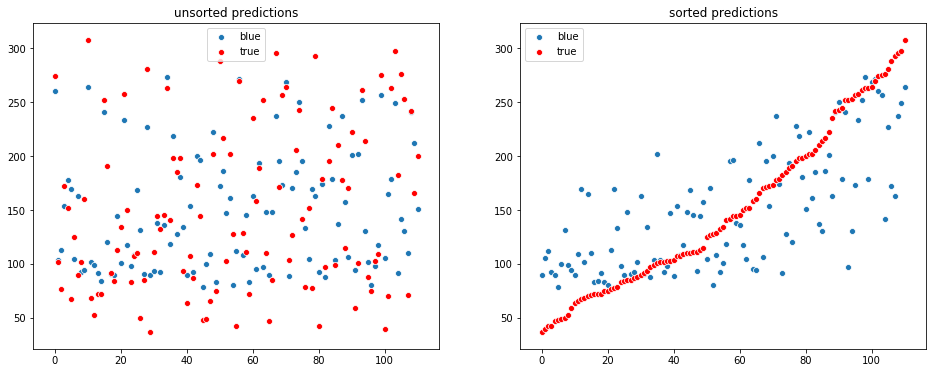
Deep Learning
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping
from tensorflow import set_random_seed
from sklearn.preprocessing import StandardScaler
np.random.seed(0)
set_random_seed(0)
# Data
x_train, y_train, x_test, y_test, columns = regression_data()
# Scaling
x_scaler = StandardScaler()
x_train = x_scaler.fit_transform(x_train)
x_test = x_scaler.transform(x_test)
y_scaler = StandardScaler()
y_train = y_scaler.fit_transform(y_train.reshape(-1, 1))
model = Sequential()
model.add(Dense(128, input_shape=(10,), activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dropout(rate=0.3))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='linear'))
model.compile(loss='mse', optimizer='adam',)
es = EarlyStopping(monitor='val_loss', patience=20)
model.fit(x_train, y_train, batch_size=32, epochs=64, validation_data=(x_test, y_test),
callbacks=[es], verbose=0)
y_pred = model.predict(x_test)
y_pred = y_scaler.inverse_transform(y_pred).reshape(-1)
visualize_regression(y_test, y_pred)RMSE: 57.605759295077384
R^2 : 0.6467517407185776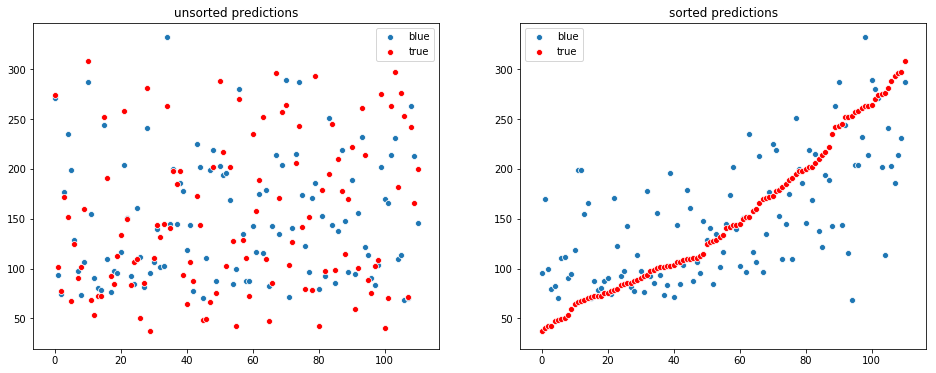
Auto-Sklearn
Installation
설치는 다음과 같이 합니다.
sudo pip install auto-sklearn
Seachspace 줄이기
Seachspace를 줄이기 위해서는 다음과 같이 합니다.
automl = autosklearn.classification.AutoSklearnClassifier(
include_estimators=["random_forest", ], exclude_estimators=None,
include_preprocessors=["no_preprocessing", ], exclude_preprocessors=None)
Auto-Sklearn은 data preprocessing 그리고 feature preprocessing 두가지로 나뉩니다.
data preprocessing은 현재 없앨수 없으며, feature preprocessing은 include_preprocessors=["no_preprocessing"] 으로 끌수 있습니다.
Data Preprocessing : 끌수 없음
- one hot encoding of categorical features
- imputation of missing values
- normalization of features or samples
Feature Preprocessing: 끌수 있음
- Feature selection
- Trasformation of features into a different space (PCA)
string 부분은 아래 링크의 파일 이름을 적으면 됩니다.
Regression Example
학습은 다음과 같이 합니다.
from autosklearn.regression import AutoSklearnRegressor
import warnings
warnings.simplefilter("ignore", category=RuntimeWarning)
x_train, y_train, x_test, y_test, columns = regression_data()
automl = AutoSklearnRegressor(time_left_for_this_task=300,
include_preprocessors=["no_preprocessing"],
per_run_time_limit=30,
n_jobs=32)
automl.fit(x_train, y_train, x_test, y_test)Inference는 다음과 같이 합니다.
y_pred = automl.predict(x_test)
print(automl.sprint_statistics())
print()
visualize_regression(y_test, y_pred)auto-sklearn results:
Dataset name: 3fe0d00d6db20f82286eea617111a6ed
Metric: r2
Best validation score: 0.549249
Number of target algorithm runs: 6812
Number of successful target algorithm runs: 5897
Number of crashed target algorithm runs: 854
Number of target algorithms that exceeded the time limit: 61
Number of target algorithms that exceeded the memory limit: 0
RMSE: 51.39984733897281
R^2 : 0.7327162464614351직접 모델을 불러와서 하는 것은 다음과 같이 합니다.
y_preds = []
for weight, model in automl.get_models_with_weights():
y_pred = model.predict(x_test)
y_preds.append(y_pred * weight)
y_pred = np.sum(y_preds, axis=0)
visualize_regression(y_test, y_pred)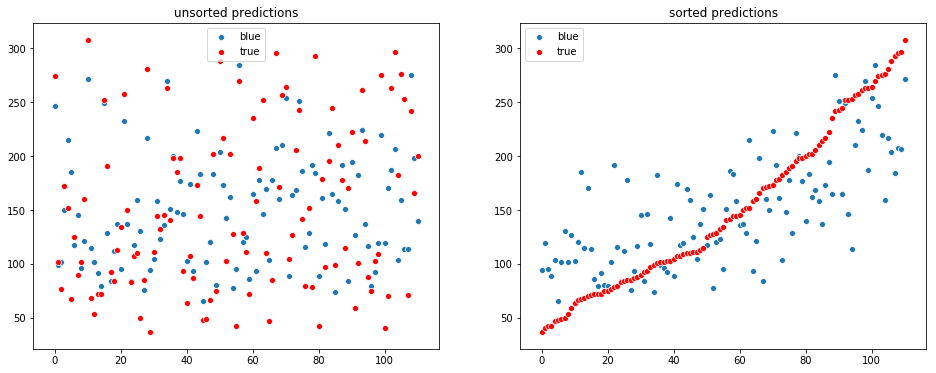
MLBox
설치는 다음과 같이 합니다.
sudo pip install mlbox
Reading Data
- train 그리고 test 데이터 구분 방법은 y 컬럼이 있는지 없는지로 구분
- 반드시 csv 파일로 읽어야 됨
from mlbox.preprocessing import Reader, Drift_thresholder
from mlbox.optimisation import Optimiser
from mlbox.prediction import Predictor
from mlbox.model.regression import Regressor
# Data
x_train, y_train, x_test, y_test, columns = regression_data()
if not os.path.exists('test.csv'):
pd.DataFrame(np.c_[x_train, y_train], columns=columns + ['y']).to_csv('train.csv')
pd.DataFrame(x_test, columns=columns).to_csv('test.csv')
# Make Reader
paths = ['train.csv', 'test.csv']
rd = Reader(sep=',', to_path='mlbox_save')
rd_data = rd.train_test_split(paths, target_name='y')
# Drift Thresholding
# 자동으로 id 그리고 drifting variables을 삭제 시킵니다.
rd_data = Drift_thresholder(to_path='mlbox_save').fit_transform(rd_data)Optimization
optimization을 하기 위해서는 다음과 같이 합니다.
- ne: missing data encoder
- ce: categorical variables
- fs: feature selector
- stck: meta-features stacker
- est: final estimator
space = {
'ne__numerical_strategy': {'space': [0, 'mean', 'median', None]},
'fs__strategy': {"space": ["variance", "rf_feature_importance", 'l1']},
'fs__threshold': {"search": "choice", "space": [0.01, 0.05, 0.1, 0.2, 0.3]},
'est__strategy': {'space': ['LightGBM', ]}, # 'RandomForest', 'AdaBoost', 'Bagging'
'est__boosting_type': {'search': 'choice', 'space': ['gbdt', 'dart', 'goss', 'rf']},
'est__num_leaves': {'search': 'choice', 'space': [25, 30, 35, 40]},
'est__learning_rate': {'search': 'choice', 'space': [0.05, 0.1, 0.2]},
'est__n_estimator': {'search': 'choice', 'space': [36, 48, 64]}
}
opt = Optimiser()
best = opt.optimise(space, rd_data, max_evals=100)Prediction
pred = Predictor(to_path='mlbox_save').fit_predict(best, rd_data)
y_pred = np.loadtxt('mlbox_save/y_predictions.csv', skiprows=1, delimiter=',')[:, 1]
visualize_regression(y_test, y_pred)RMSE: 55.54996340032959
R^2 : 0.6775444386655826