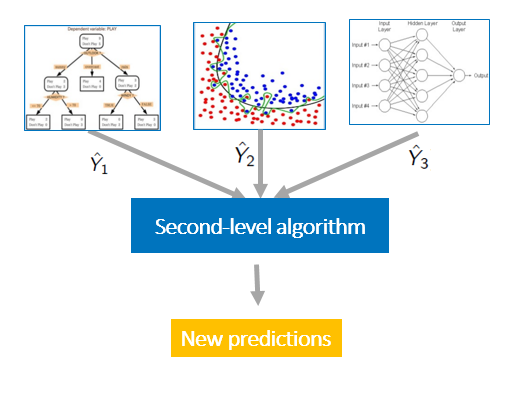
Ensemble / Bias and Variance Tradeoff / Bagging VS Boosting
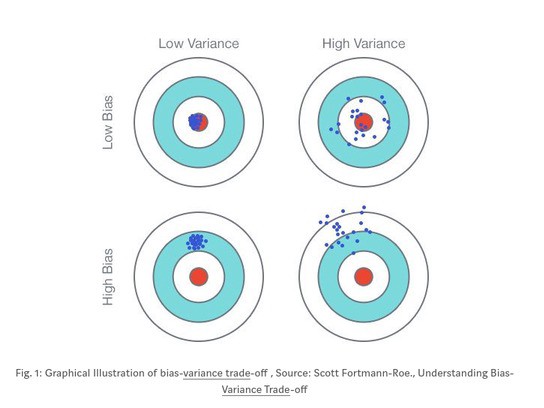
1. Bias and Variance Tradeoff
1.1 Error
\[Error = noise(x) + bias(x) + variance(x)\]- error: irreducible error 로서 제거 할수 없는 존재..
- bias 그리고 variance: 서로 tradeoff 관계에 있으며 적절하게 조정해서 minimize 하는게 목적
1.2 Bias
Bias는 예측된 값과 기대값(GT) 차이라고 볼 수 있습니다.
\[\text{Bias} = E[y - \hat{y}]\]- Bias는 예측관 값과 Ground Truth 값과의 차이의 평균입니다.
- Low Bias: 약한 가정 / 오차가 적다 (Decision Tree, KNN, SVM)
- High Bias: 강한 가정 / 오차가 크다 (Linear Regression, Linear Discriminant Analysis, Logistic Regression)
1.3 Variance
\[\text{Variance} = E \left[ \hat{y} - E[\hat{y}] \right]^2\]- 예측값과 예측값들의 평균의 차를 제곱해준 것입니다.
- 즉 예측값들끼리 얼마나 퍼져 있는지, 좁게 몰려 있는지를 나타낸 것입니다.
- Low Variance:
- High Variance: 모든 데이터들을 지나치게 학습
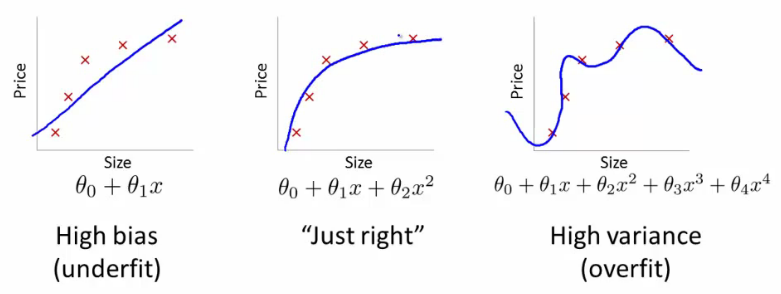
1.4 Underfitting and Overfitting
- Underfitting : High Bias and Low Variance
- 모델은 예측시 강한 가정(assumption)을 갖고 있음.
- 데이터 부족으로 정확한 모델을 만들 수 없을 때 발생
- Linear Model 을 Non-Linear Data 에 적용할때 발생
- Overfitting : Low Bias and High Variance
- 노이즈 데이터까지 피팅 시켜서 발생함
- 복잡한 모델을 단순한 데이터에 적용시 발생
2. Ensemble - Bagging VS Boosting
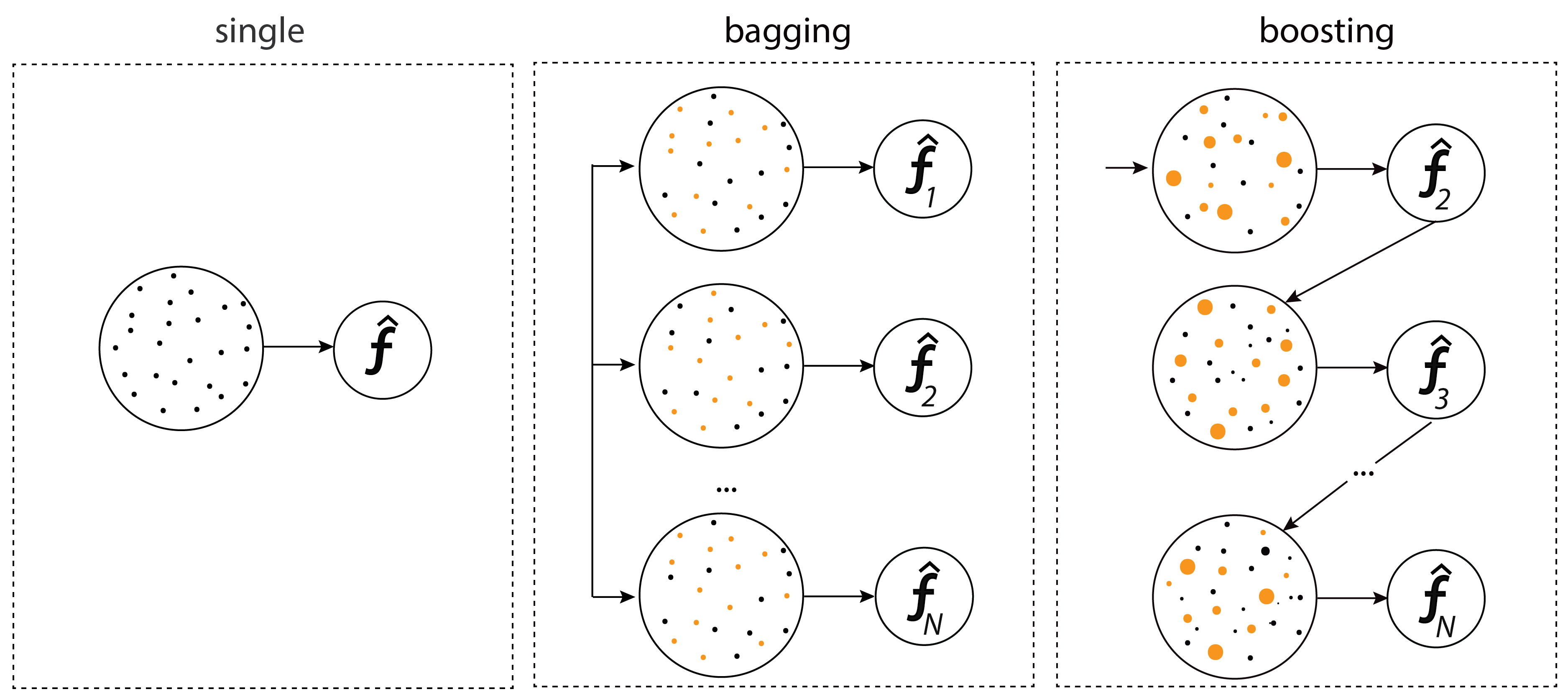
2.1 Bagging - Bootstrap Aggregation
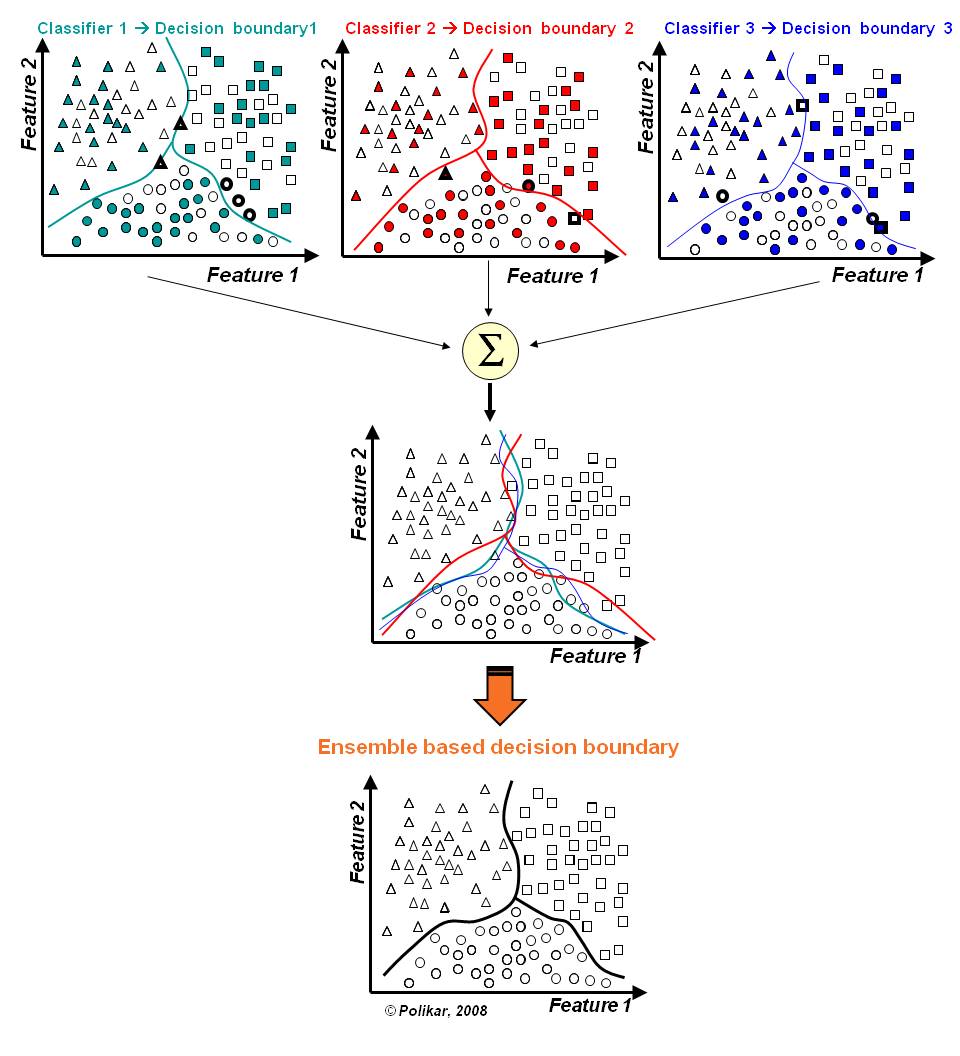
- Partitioning Data: Random
- Goal: Variance 최소화
- Method: Random Subspace
- Combine method: weighted average
- Models: Random Forest
- 장점
- Over-fitting 문제를 해결 (특히 decision tree -> random forest로 전환시)
- missing data가 발생해도 accuracy를 유지함
Regression Problem
\[F_{bag}(x) = \frac{1}{B} \sum^B_{b=1} f_b(x)\]Classification Problem
\[F_{bag}(x) = sign\left( \sum^B_{b=1} f_b(x) \right)\]Steps
- n observations 그리고 m features 가 트레이닝 데이터에 존재
- m features 중의 일부가 샘플로 랜덤 선택이 되며, n observations 에서도 샘플로 선택.
- 모델은 랜덤으로 선택된 features 를 기반으로 학습을 하게 됩니다.
- 2번 3번을 반복하며 여러개의 모델을 학습시킵니다.
- prediction은 해당 학습된 여러개의 모델이 예측한 값을 aggregation해서 예측값을 결정합니다.
2.2 Boosting
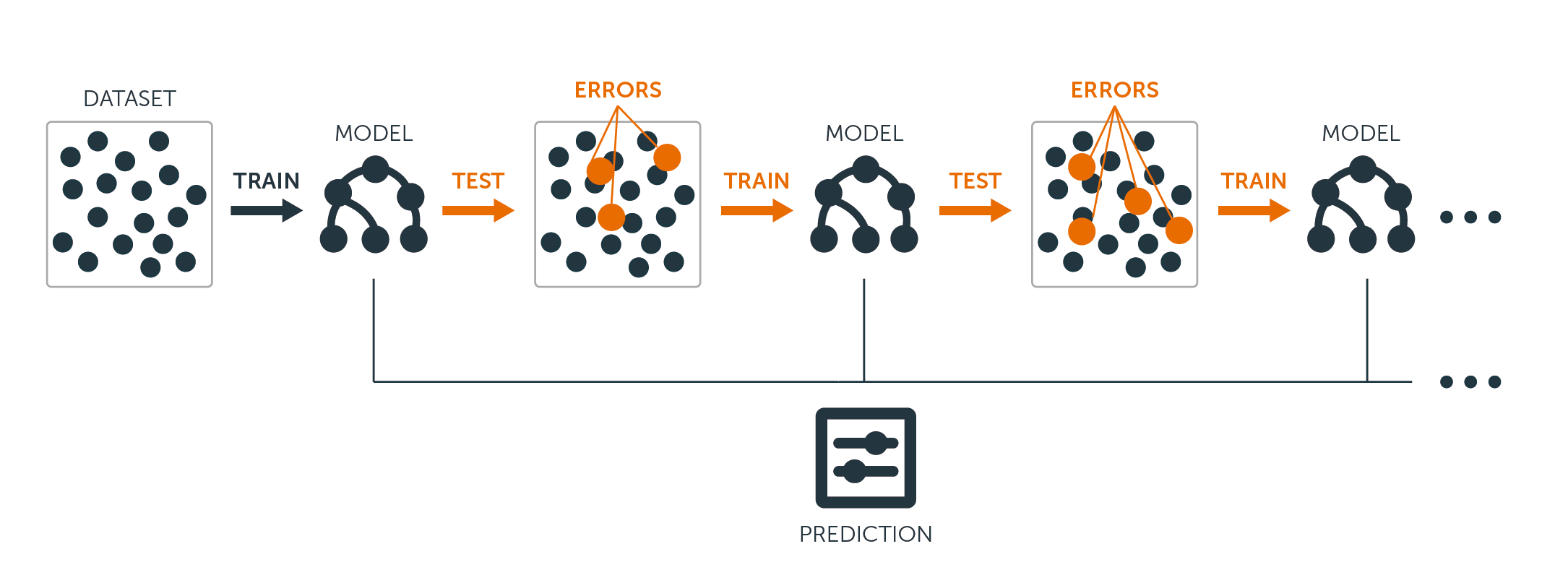
- Partitioning Data: Higher vote to misclassified samples
- Goal: Accuracy 향상
- Method: Gradient Descent
- Combine Method: Weighted Majority Vote
- Models: Ada Boost, XGBoost, LightGBM, Catboost
- 장점:
- 복잡한 문제를 푸는데 예측을 잘함. 경험상으로도 그러함.
- 단점:
- Overfitting
Steps
방식은 꽤 많은데.. 핵심은 에러로 나온 에러 데이터에 가중치를 더해서 그 다음 모델에서 다시 학습시킴.
이후 여러개의 모델이 만들어지면 최종 prediction에서는 각 모델의 가중평균을 내서 결과값을 도출
- 데이터에서 램던 샘플을 취하고 weak leaner M1 을 학습시킨다.
- training dataset 에서 랜덤샘플을 신규로 취하고, 이전 모델에서 잘못 예측한 데이터셋 50%를 추가 함. -> weak leaner M2 를 학습
- 반복적으로 여러개의 모델을 sequentially 만듬.
- prediction시에는 예를 들어 5개의 weak leaners 가 있고, [1, 1, 1, -1, -1] 이렇게 예측후, 각 모델마다의 가중치 [0.2, 0.5, 0.2, 0.8, 0.9] 를 곱한후 합치면 -0.8이 나오며, 최종값은 -1이 된다
2.3 Stacking