ML Interview Questions
1. Basic Interview Questions
1.1 Bias - Variance Tradeoff
- Bias: underfitting
- Variance: Overfitting
중간지점을 잘 찾아서 균형을 찾는게 관건.
- Bias 줄이기
- linear model -> Polynomial, Deep Network
- 학습 시간 늘리기,
- feature engineering, loss function 개선
- Variance 줄이기
- L1, L2, Dropout 같은 regularization 추가
- pruning, depth 줄이기
- 더 많은 데이터 추가
- Bagging, Boosting 같은 ensemble learning 사용 (random forest)
수학적으로 설명
- Bias: 모델 평균 예측값 - 실제 f(x) 차이 : \(\left( f(x) - E\left[ \hat{f}(x) \right] \right)^2\)
- Variance: 모델 예측값 - 모델 예측값의 평균값 : \(E \left[ \left(\hat{f}(x) - E\left[ \hat{f}(x) \right] \right)^2 \right]\)
Bias Variance Decomposition 저 위의 공식이 나옴. 제곱 있는건 MSE에서 decomsition 해서 그러함.

2. ML Performance
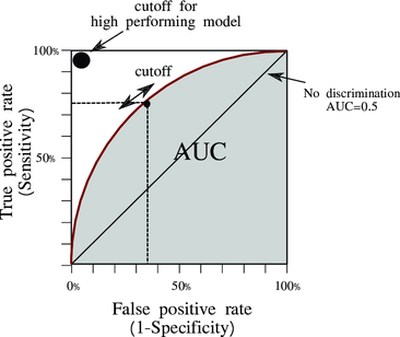
2.1 ROC AUC
ROC
- ROC: Receiver Operating Characteristic curve
- X축: FPR (False Positive Rate) \(FPR = \frac{FP}{FP + TN}\)
- Y축: TPR (True Positive Rate) \(TPR = \frac{TP}{TP + FN}\)
- threshold 를 움직이면서 각각을 모두 계산하는 방법
- ex) threshold = 0.7 이면 0.7이상은 positive 이고, 이하는 negative 로 설정
ROC AUC
- ROC Curve 아래 면적 (Area Under Curve)
- 수치
- 0.5: 랜덤
- 1.0: 완벽 구분
- 0: 완전히 반대로 예측
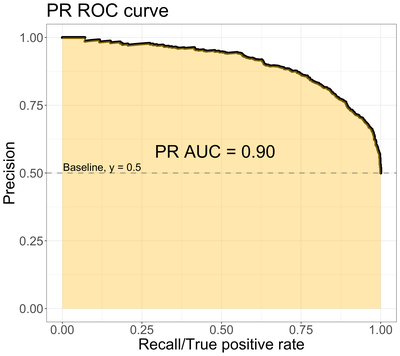
2.2 PrAUC
- x축: \(Recall = \frac{TP}{TP + FN}\) (positive로 예측한것 중에 진짜 positive 비율)
- y축: \(Precision = \frac{TP}{TP + FP}\)
해석
- recall: 실제 y=1 에서 모델이 positive를 맞춘 비율
- precision: 모델이 y_predict = 1 로 예측한것 중에 실제 맞춘 비율
- 관계
- recall 과 precision은 서로 trade-off 관계
- 모든 값을 y_predict = 1 로 예측시 recall 은 1이 나옴
- 엄청나게 확신갖는것만 y_predict = 1 로 예측시 precision은 높아짐 하지만 recall은 낮아짐
- PrAUC 는 positive가 매우 적은 상황에서 accuracy 보다 더 신뢰 할수 있음.
2.2 Precision@K and Recall@K
- Precision@K (P@K)
- \[Precision@K = \frac{\text{Top K 중 실제 구매한 상품 수}}{K}\]
- K: 상위 K 추천된 상품 수
- 유저가 실제 클릭/구매 확률이 높은지를 랭킹에서 보기 때문에 매우 중요
- Recall@K
- \[Recall@K = = \frac{\text{Top K 중 실제 구매한 상품 수}}{전체 구매 상품 갯수}\]
- 유저가 리스트중에서 한개를 구매하는게 아니라 여러개 구매 가능시 중요
- 쿠팡이나 아마존은 아님
2.3 mAP (Mean Average Precision)
Average Precision