Basic Engineering 101 for ML Engineers
- 1. Introduction
- 2. Server Engineering 101 for ML Engineers
- 2.1 Subnet에 대해서 간략하게 설명.
- 2.2 서브네팅 계산하는 방법은?
- 2.3 CAP 이론에 대해서 설명해 달라.
- 2.4 Concurrency, Asynchronous 그리고 Parallelism 차이점은?
- 2.5 Monolithic, SOA, 그리고 MSA 의 차이점은?
- 2.6 언제 NOSQL 사용 하는 것이 좋은가?
- 2.7 Sharding 의 단점은 무엇인가?
- 2.8 ACID 설명
- 2.9 Scalability 그리고 Elasticity 에 대해서 설명
- 2.10 TCP VS UDP 차이점?
- 2.11 RDBMS VS NOSQL
- 2.12 Single Sign-On (SSO) 란 무엇인가? `
- 2.13 CI/CD 설명
- 2.14 Stateful VS Stateless
- 2.15 OSI Model
- 2.16 RPO and RTO 에 대해서 설명
- 2.17 RAID 설명
- 2.18 Disaster Recovery VS Fault Tolerance 차이는?
- 2.19 Saga Pattern 에 대해서 설명
- 2.20 AVRO VS ORC VS Parquet 차이에 대해서 설명
- 3. Software Engineering 101 for ML Engineers
- 4. Security

계속 작성중 입니다.
1. Introduction
머신러닝 엔지니어로서 알아야할 엔지니어링의 기본적인 소양을 적었습니다.
본문에서는 분량상 머신러닝, 딥러닝, 통계등은 다루지 않겠습니다.
개인적으로 특정 기술을 할줄 아냐 모르냐 보다도.. 기본이 되어 있냐를 중요시 생각합니다.
어차피 특정 기술이나.. 모델링 같은 것들은 그냥 배우면 됩니다.
예를 들어서 카카오 모빌리티에서 AI팀장을 했을때는 직접적인 모델링 보다도 수학이나 통계같은 근본적인 질문들을 많이 했습니다.
또는 복잡한 알고리즘 보다는 핵심적이고.. 단 몇줄만에 끝나는 알고리즘들을 문제를 냈고요.
그래서.. 제 기준에서는 모델링도, 딥러닝도, 수학도, 코딩도, 엔지니어링도.. 모두 기본이 중요하지..
당장 최신 논문을 아냐 모르냐.. 최신 라이브러리를 아냐 모르냐.. 이건 별로 중요하지 않습니다.
엔지니어링은 매우 중요합니다.
특히 짬밥이 늘어날수록.. 점점 규모가 큰 설계를 책임지게 될 가능성이 높아지게 됩니다.
그리고 이런 분야는 경험이 중요합니다.
좋은 모델을 만들어 놓고도, 어떤 엔지니어링으로 실제 서비스에 구현이 들어가야 하는가는 또 전혀 다른 이야기 입니다.
예를 들어서 euclidean distance 같은 간단한 수식도, 이걸.. 수천억개의 데이터속에서 빠르게 처리하는 것은 급이 다릅니다.
Python에서 numpy로 돌리는 것과, 빅데이터에서 얼마만큼의 latency제약속에서 계산을 빠르게 할거냐.. 캐쉬는 어떻게 처리할거냐..
실시간이냐, 니어 리얼 타임이냐. 아니면 일배치로도 가능하냐.. 다른 제약 조건은 없는가? 다른 잡들과의 리소스 분배는 어떻게 할 것이냐..
레이어 설계는 어떻게 할 것이며, 데이터 파이프라인은 어떻게 잡을 것인지.. 등등…
별거 아닌거 같겠지만, 실제 현업에서 아키텍쳐의 차이로 퍼포먼스의 차이는 크다고 볼 수 있습니다.
여기서 말하는 퍼포먼스는 단순히 latency 뿐만 아니라 생산성도 포함합니다.
하여튼.. 포인트는 아주 기초적인 부분만 정리 했습니다. <– 이건 좀 알아아라 ..
2. Server Engineering 101 for ML Engineers
2.1 Subnet에 대해서 간략하게 설명.
IP주소는 한정적이기 때문에, 이것을 극복하기 위해서 나온 개념이며,
보통 외부 IP, 그리고 내부 IP로 나눠서 사용하며, 나누는 방법은 “서브넷 마스크”를 사용합니다.
예를 들어 IP주소 192.168.200.1 에서 서브넷 마스크 255.255.255.0 으로 가정했을때,
255부분은 네트워크 ID 부분이고, 0에 해당하는 것이 호스트 ID 부분이며,
0으로 된 부분에서 IP를 나눠 쓰게 됩니다.
| Name | Value | Bits | Description |
|---|---|---|---|
| IP Address | 192.168.200.1/24 | 11000000.10101000.11001000.00000001 | 24라는 뜻은, 왼쪽부터 1의 갯수를 의미 |
| Subnet Mask | 255.255.255.0 | 11111111.11111111.11111111.00000000 | 1: Network ID, 0: Host ID |
2.2 서브네팅 계산하는 방법은?
AND operation을 해서 IP Address가 동일하면 됩니다.
아래 Python 참고
> from netaddr import IPNetwork, IPAddress
>
> addr = IPNetwork('192.168.200.1') # 192.168.200.1 한개만 사용 가능
> addr.ip.bits()
'11000000.10101000.11001000.00000001'
> addr.netmask, addr.hostmask, addr.size
(IPAddress('255.255.255.255'), IPAddress('0.0.0.0'), 1)
> IPAddress('192.168.200.1') in addr, IPAddress('192.168.200.255') in addr
True, False> addr = IPNetwork('192.168.200.1/24') # 192.168.200.0 ~ 192.168.200.255 까지 사용 가능
> addr.ip.bits()
'11000000.10101000.11001000.00000001'
> addr.netmask, addr.hostmask, addr.size
(IPAddress('255.255.255.0'), IPAddress('0.0.0.255'), 256)
> IPAddress('192.168.200.1') in addr, IPAddress('192.168.200.255') in addr
True, True2.3 CAP 이론에 대해서 설명해 달라.
CAP 이론은 어떠한 분산 시스템도 일관성 (Consistency), 가용성 (Availability), 그리고 분할내성 (Partition Tolerence)..
이 모두를 만족시키는 시스템은 없다는 이론입니다.
- Consistency: concurrent update가 진행되는 중에, 모든 노드가 동일한 데이터를 읽을 수 있는 것 (ex. RDBMS 슬레이브 DB는 X)
- Availability: 몇몇 노드의 장애시에도 정상적인 응답을 받는 것. A노드가 망가져도, B노드에서 처리 가능
- Partition Tolerance: 물리적 네트워크 장애가 있더라도 정상작동 하는지 여부. 물리적 네트워크 장애로 A와 B가 연결이 안될때..
계속 작동시킨다면, consistency에 문제가 생기고, consistency를 위해서 네트워크 장애가 해결될때까지 기다리면 가용성이 떨어짐
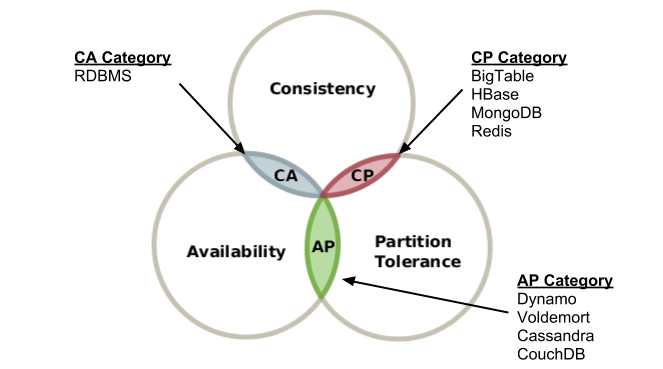
CAP의 단점들
- CP: 일관성 + 분산 시스템을 살린다면, 모든 데이터의 업데이트는 완벽하게 복제되야 하며, 성능을 떨어뜨린다
- AP: 가용성 + 분산 시스템을 살린다면, 노드가 다운되거나, 물리적 네트워크가 망가져도 정상작동하지만, 일관성은 반드시 깨진다
- CA: 일관성 + 가용성을 살린다면, 네트워크 장애가 절대 일어나지 말아야 하지만, 그런건 세상에 없다.
따라서 P는 무조건 강제선택이고, 실제로는 C와 A 사이에서의 고민이다.
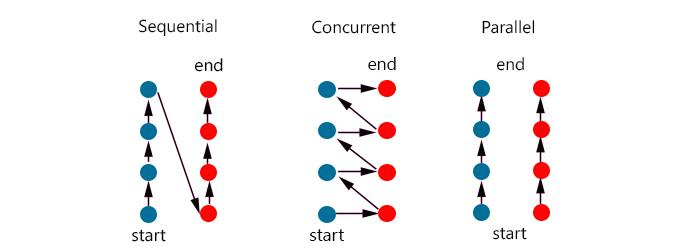
2.4 Concurrency, Asynchronous 그리고 Parallelism 차이점은?
- Asynchronous: 뭔가를 실행시켰을때, non-blocking으로 실행된다. ->
callback을 사용해서 처리 - Parallelism : 병렬성은 동시에 여러개를 실행시키는 것을 의미 한다 -> 큰 작업을 작게 나눠서
멀티 코어에서 여러개로 실행 - Concurrency : 동시성은 여러개의 독립적인 작업들을 순서를 한꺼번에 처리하는 것처럼 보임 ->
싱클 코어에서 여러개의 쓰레드가 작업을 하는 것
2.5 Monolithic, SOA, 그리고 MSA 의 차이점은?
- Monolithic Architecture: 그냥 하나의 거대한 컨테이너 안에 다 때려박는 걸 의미 함. -> 서버 하나에서 모든 기능을 다 수행
- Service-Oriented Architecture: 서비스별로 서버 기능을 나누고, 서로간에는 통신을 함 -> 카카오 대리 <-> AI 플랫폼 <-> 카카오 택시
- 모듈의 의존성은 줄이되, 공유할수 있는건 최대한 공유
DB를 공통으로 사용
- Microservice Architecture: SOA와 유사하나 비즈니스 단위로 더 나누어서 설계
- 가능한 공유하지 않고, 모두다 독립적으로 운영되도록 설계
DB를 모두 제각각 운영
MSA가 쉬워 보이나.. 나중에 실무적인 측면에서 관리가 꽤 복잡해짐.
개인적인 생각은 MSA하려면 그만큼 충분한 인원이 필요함.
인원이 부족한 스타트업에서는 MSA보다는 그냥 빠르게 치고 나갈수 있는 monolithic 도 괜찮다고 생각함
2.6 언제 NOSQL 사용 하는 것이 좋은가?
RDBMS는 ACID를 강제합니다. 따라서 schema를 기초로한 데이터를 적재할 수 있으며, 사실.. 대부분의 업무는 RDBMS로 다 끝낼수 있습니다.
다만 RDBMS가 부족한 부분은, 고가용성 (high availability)가 반드시 필요한 데이터에서 속도, 그리고 scalability 이슈가 생길수 있습니다.
예를 들어 구글, 아마존은 테라바이트 단위의 데이터를 빅데이터에 적재를 합니다.
만약 RDBMS에서 쿼리를 처리시 blocking, schema, transaction같은 기술적인 이유들로 인해서 퍼포먼스에 제한을 받게 됩니다.
정리를 하면 다음과 같습니다 .
- 99.99% High Availability 가 필요로 할때
- SQL에 적합하지 않는 데이터일 경우. -> join시키기 어려운 데이터
- 관계형 모델을 해칠때 -> schemaless 데이터 또는 이미지, 음성같은 비정형 데이터, 또는.. 엄청나게 큰 텍스트에서 검색
2.7 Sharding 의 단점은 무엇인가?
Sharding은 간단하게 말하면, table안의 rows를 나눠서, 다수의 데이터베이스에 분산하여 저장하는 방법을 의미합니다.
일종의 horizontal partitioning 입니다.
생각보다 매우 까다로울 수 있습니다.
- 잘못 분산된 sharding은 특정 database에서만 hotspot이 생기게 되며, 성능이 느려지게 됩니다.
- application단에서 복잡도가 올라가게 됩니다.
- 노드의 추가 또는 삭제는 데이터 rebalance를 거쳐야 합니다.
- cross node join 이 필요시, 성능이 심각하게 느려질수 있습니다. 따라서 어떻게 데이터가 사용될지도 함께 고민이 되야 합니다.
2.8 ACID 설명
- Atomicity (원자성): 트랜잭션의 부분적 실행이나 중단이 되지 않는 것을 의미. 즉 All or Nothing의 개념
- Consistency (일관성): 트랜잭션 이후 데이터 타입이나 상태가 일관성 있게 유지 되는 것을 의미 (int 가 갑자기 string이 되는 일은 없다)
- Isolation (격리성): 트랜잭션 수행중, 다른 트랜잭션의 작업이 끼어들지 못하는 것을 의미
- Durability (지속성): 트랜잭션 성공하면, 데이터는 성공한 이후로 그대로 보장됨 -> commit 하면 그걸로 끝
2.9 Scalability 그리고 Elasticity 에 대해서 설명
- Scalability: workload가 증가할시, 리소스를 더 추가하는 것.
- Scale Up: CPU, 메모리 등등 하드웨어 리소스를 추가해서 증가 시키는 것
- Scale Out: 추가적인 node (서버)를 추가 하는 것
- Elasticity : 현재 필요한 workload에 따라서,
자동으로 리소스를 증가시키거나 줄임으로서, 필요한 자원의 양에 최대한 정확하게 맞추는 것을 의미- 즉
자동부분과필요한 자원에 최대한 맞추는 것이 scalability와의 차이입니다.
- 즉
즉.. 서버에 requests가 많이 들어오게 되면, 미리 정한 측정 요소대로, Elasticity를 통해서
자동으로 Scale up 또는 Scale out 을 진행하게 됩니다.
결국 미리 정한 측정 요소(ex. CPU Load)와 자동으로 필요한 요소에 맞추는 것을 의미함
2.10 TCP VS UDP 차이점?
- TCP
- 3-way handshaking 을 통해서 연결 (클라
SYN-> 서버SYN-ACK-> 클라ACK) - 4-way handshaking 을 통해서 해제 (클라
FIN-> 서버ACK,FIN-> 클라ACK) - 즉 TCP Header 또한 복잡하지만, handshake 그리고, ACK 제어비트를 통해서 잘 도착했는지 확인까지 하기 때문에 느리다.
- 3-way handshaking 을 통해서 연결 (클라
- UDP
- UDP는 비연결형 이기 때문에, TCP처럼 handshake 를 하지 않습니다.
- Retransmission 없음: dropped packet 을 다시 보내지 않는다.
따라서 Voice over IP (VoIP), FPS 게임의 총알, 스트리밍에 적합합니다. - UDP의 headers
- Client Port, Server Port, Data 길이, checksum 으로 이루어 져 있습니다. <- 간결하기 때문에 속도가 더 빠릅니다.
자세한 내용은 링크 참조합니다.
2.11 RDBMS VS NOSQL
| Key | RDBMS | NOSQL |
|---|---|---|
| Structure | Tabular 구조로 데이터를 저장 | 정형, 비정형 등등 다양한 형태로 저장 |
| ACID | ACID를 따르기 때문에 consistency를 추구 | ACID 서포트 없음 |
| Distributed | Distributed Database 지원 | Distributed Database 지원 |
| 데이터 크기 | 큰 데이터에도 나쁘지는 않다 | 빅데이터급 또는 실시간 데이터 (로그성 데이터) |
| 관계형 | Foreign Key 등으로 데이터간의 연결 가능 | 그냥 single document file로 저장됨 |
| UPDATE | 빠름 | UPDATE를 못할수도 있거나, 느림 |
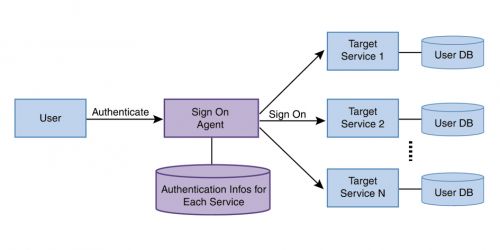
2.12 Single Sign-On (SSO) 란 무엇인가? `
한번의 로그인 인증으로 여러개의 서비스를 추가적인 인증 없이 사용할 수 있는 기술.
두가지 방식이 존재 합니다.
- Delegation: 사용자 인증 정보를 SSO 에이전트가 관리하며 로그인 대신 수행
- Propagation: SSO에서 인증을 수행하고, 토큰을 발급 -> 해당 토큰으로 인증 수행
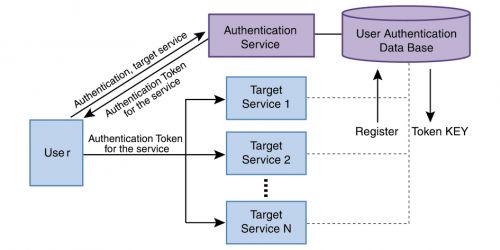
2.13 CI/CD 설명
새로운 버젼의 소프트웨어를 릴리즈시에 수행되며, build, test, release, deploy, validation 등이 모두 자동화 배포 되는 것 입니다.
- CI: Continuous Integration
- build, test 과정을 거치게 됩니다.
- 많은 개발자분들이 코드 수정/추가시마다 commit을 하게 되는데, 이때마다 자동으로 빌드 -> 테스트를 자동화 한것
- 참고로 master branch 로 merge는 사람이 manual로 ㅎㅎ
- CD: Continuous Delivery
- 자동으로 production으로 수정 또는 새로운 코드를 배포 하는 과정
CI/CD는 다음과 같은 과정을 거치게 됩니다.
- Code Commit: 코드 변경후 -> git commit 이후 -> push
- Build (CI): code compile 수행 -> 여기부터 Jenkins가 실행. 코드 컴파일 실행 / Docker의 경우 build 실행
- Test (CI) : 테스트를 자동으로 실행 -> 테스트 실행
- Release (CD): Production으로 배포
- Docker의 경우 Container Registry로 올리고 -> Kubernetes에서 새로운 docker container를 배포 실행
정말 다양한 방법으로 pipeline 설계가 가능한데.. 그냥 간단하게만 설명한 것입니다.
2.14 Stateful VS Stateless
상태정보를 클라쪽에서 저장하냐, 아니면 서버쪽에서 저장하는가로 기준이 나뉩니다.
- Stateless
- every transaction is performed as if it were being done for the very first time.
There is no previously stored information used for the current transaction - Stateless는 이전의 request/transaction에서 처리된 정보를 서버 어딘가에 저장해 놓는 것이 아니라,
request가 올때마다 마치 새로운 정보를 다루듯이 처리를 하는 방식입니다. - 각각의 requests들은 모두 다른 서버에서 처리가 될 수 있습니다. -> Scalability!
- every transaction is performed as if it were being done for the very first time.
- Stateful
- keep track of the previously stored information which is used for current transaction
- TCP를 이용해서 연결을 이어놓던가, 또는 단일 서버에서 처리를 하거나, 로드 밸러서에서 IP Affinity를 걸어 놓습니다.
- 단일 서버를 사용할수 밖에 없는데, 자… cookie 못 사용하고, header에 내가 누구다 밝힐수 없고, 무조건 서버쪽에서 들고 있어야 하니..
단일 서버와 연결을 강제로 시켜줄수 밖에 없죠. - 문제가 되는 부분이 바로 MSA를 도입할때 입니다.
MSA 도입시, 모든 서버의 dependency를 끊어 놓기 때문에 (심지어 DB도 각자 이용) Stateful은 이 부분에서 Scalable 하지 않습니다.
또한 로드 밸런서에서 IP Affinity를 설정한다고 하더라도, 특정 서버로만 트래픽이 몰릴경우 문제가 발생할 수 있습니다.
2.15 OSI Model
설명이 가장 잘 되어 있으며 그림을 가져온 곳 링크
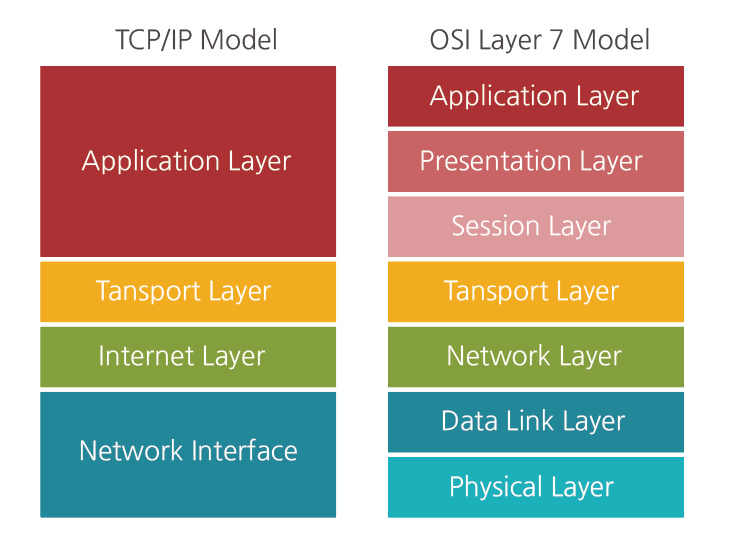
- Physical Layer
- 케이블, 랜선, 허브, 모뎀 등등 물리적인 영역
- 데이터는 1, 0 같은 비트 스트림으로 변환되서 물리적 전송을 담당
- Data Link Layer
- 기기와 기기 사이의 데이터 전송 부분을 말함
- 데이터는 packet 단위에서
frame으로 잘려서 전송이 되며, physical layer에서 발생할 물리적 전송 결함을 정정한다 - 이더넷, 브릿지, 스위치 같은 장비들
- Network Layer
- 데이터는 segments 단위에서
packets단위로 나뉜다 Routing을 통해서 최적의 경로를 찾아낸다
- 데이터는 segments 단위에서
- Transport Layer
- 데이터는
segments단위로 나뉘게 된다. - flow control, 전송상의 에러 복구, 전송 대역등을 담당
- 데이터는
- Session Layer
- 두 애플리케이션간의 연결을 설정, 유지 해제를 담당
- 데이터 중간마다
syn동기점을 삽입하여, 연결이 단절되거나 전송 오류가 발생시 -> syn 지점부터 다시 시작해서 처음부터 데이터를 다시 보내지 않도록 방지 한다
- Presentation Layer
- 데이터 변환, 암호화, 압축을 담당
- HTTPS 사용시 데이터 암호화 하거나, 바이너리로 들어온 JPG, PNG등을 우리가 볼 수 있는 형태로 변환
- Application Layer
- 당신이 사용하는 소프트웨어 (웹브라우저, 이메일, Office365 등등)
2.16 RPO and RTO 에 대해서 설명
- RPO (Recovery Point Objective): 목표 복구 시점
- RTO (Recovery Time Objective): 목표 복구 시간 (걸리는 시간)
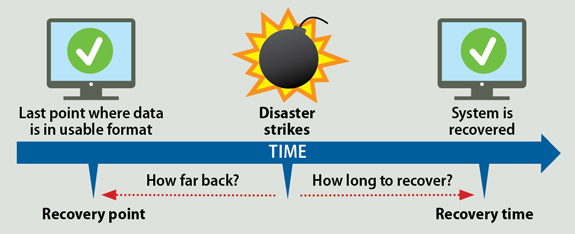
고가용성과 관련된 내용이고, 데이터 유실을 얼마나 허용할 것인지, 그리고 얼마나 빨리 복구 할 것인지에 관한 내용입니다.
하지만 트레이드 오프가 발생하게 되는데, 결국 비용 VS 비즈니스 리스크 입니다.
데이터 유실을 최소한으로 가져가거나, 복구 시간을 짧게 가져가려고 한다면 -> 비용이 높아지며
데이터 유실을 크게 허용하거나, 복구 시간을 크게 가져가면 -> 비즈니스 리스크가 발생하게 됩니다.
2.17 RAID 설명
RAID (Redundant Array of Independent Disk)는 그냥.. 여러개의 디스크를 묶어서 마치 하나의 디스크 처럼 사용 하는 것을 의미 합니다.
- RAID 0
스트라이프세트- 최소 2개 디스크 필요
- 가장 빠름
- 저장시 데이터를 쪼개서 모든 디스크에 걸쳐서 write 한다
- 읽을때 여러 디스크가 동시에 읽기 때문에 빠름
- RAID 1:
미러링- 최소 2개 디스크 필요
- 하나가 고장나더라도 괜찮기 때문에 fault-torelence를 제공.
- 저장공간 효율은 떨어짐
- RAID 5
- RAID0 장점 + RAID1 장점
- 최소 3개 디스크 필요 -> 일반적으로 5개 구성
- 하드디스크 고장시 Pairty를 이용하여 복구
2.18 Disaster Recovery VS Fault Tolerance 차이는?
- High Availability (고가용성)
- 99.0 ~ 100% 사이의 고가용성을 갖는 시스템을 의미
- Fault Tolerance (내결함성)
- High Availability 와 유사하지만,
zero downtime 을 보장. 하지만 비용이 지나치게 크게 들 수 있다 - 문제가 생겼을 경우 (하드웨어든 뭐든..) -> redundant device 로 바로 교체 -> 중복으로 장비를 준비해야 되기 때문에.. 비용 넘사벽
- fault tolerance가 한글로 하면 장애 허용이라는 말인데.. 장애가 나더라도 다른 장비로 대체하기 때문임. -> 내팽겨치겠다는 뜻이 아님
- High Availability 와 유사하지만,
- Disaster Recovery (재해복구)
- disaster가 발생시 (허리케인, 지진, 홍수, 사이버 공격 등등) 시스템 정화하기 위한 일종의
플랜이라고 생각하면 됨. - 그외 복구에 걸리는 시간, Recovery point (체크포인트) 등을 설정해 놔야 함 (결국 백업 시스템)
- 플랜안에는 High availability 시스템이 구현된다.
- disaster가 발생시 (허리케인, 지진, 홍수, 사이버 공격 등등) 시스템 정화하기 위한 일종의
2.19 Saga Pattern 에 대해서 설명
MSA에서는 Database Per Service를 추구하기 때문에, 각 서비스별로 자체의 DB가 따로따로 있습니다.
문제는 consistency를 구현하는 것이 문제가 될 수 있습니다.
예를 들어서 쇼핑몰에서 주문 기능을 구현시.. 주문 서비스에서 주문을 받고, 재고 서비스에서 재고를 확인하고, 배달 서비스에서 배달을 하고..
각 서비스별로 할 일들이 있을텐데.. 중간에 문제가 발생할 수 있습니다.
이때 최종 배달까지 완료하지 못했을 경우 각 서비스 별로 롤백이 필요하게 됩니다.
하지만 MSA는 각 서비스별로 DB를 따로따로 갖고 있기 때문에, ACID 트랜잭션을 사용할수도 없습니다.
이때 Saga 패턴을 사용하게 됩니다.
트렌섹션은 다음과 같은 흐름으로 갑니다.
- 주문 -> 주문서비스 -> 결제 서비스 -> 재고 서비스 -> 배송 서비스
문제는 재고서비스에서 재고가 부족할때 발생하게 됩니다.
이미 주문 서비스, 결제 서비스의 DB에서는 commit 이 이미 되어기 때문에, commit 된 데이터를 rollback 시켜야 합니다.
이때 compensating transaction (보상 트랜섹션) 을 따로 만들어서 -> 이전 서비스들에 이벤트 요청을 보내야 합니다.
따라서 해당 이벤트에 해당되는 구현을 따로 만들어줘야 합니다. (MSA에서는 이렇게 ㅠㅠ)
2.20 AVRO VS ORC VS Parquet 차이에 대해서 설명
하둡에서 저장하는 타입으로서, 모두 binary format 이며, (json같은 형식과는 다르게) 여러개의 디스크로 나뉘어서 저장이 가능하다
이로인해 확장성 그리고 동시처리가 가능하다.
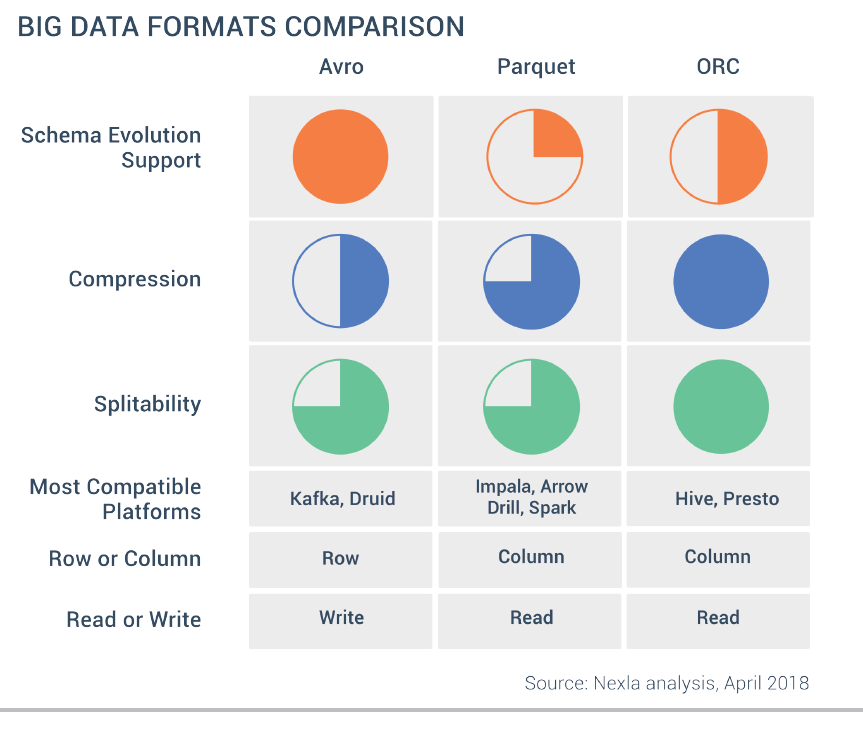
- Parquet 그리고 ORC는 column 기반으로 데이터를 저장하며, avro는 row 기반으로 저장.
- columns 기반: 특정 필드에 access가 빈번할때 빠름 / 큰 데이터를 읽어서 분석할때 최적 / 읽기 빠름
- row 기반: 모든 필드에 접근이 필요한때 빠름 / 큰 데이터를 쓸때 최적 / 쓰기 빠름
3. Software Engineering 101 for ML Engineers
3.1 Semaphore 그리고 Mutex의 차이점은?
- Mutex: 일종의 Locking System으로서 오직
하나의쓰레드 또는 프로세서만 lock 키를 acquire 할수 있다.- 오직 하나의 쓰레드만 작업을 실행 가능
- 화장실이 1개 있는 레스토랑에서, 키가 하나밖에 없으며, 화장실 사용자는 키를 얻어서 화장실 사용후 -> 다른 사람에게 건낼수 있다.
- Python에서는 global lock을 하나를 만들고, 여러개의 Threads 또는 Processors중에서 오직 하나만 acquire하고 사용 가능
- Semaphore: 일종의 Signaling System으로서, 임계영역을 설정해서
여러개의 쓰레드 또는 프로세서가 접근하는 것을 허용.- 여러개의 쓰레드가 일정한 범위 안에서 실행 가능
- 화장실이 3개가 있고, 임계영역은 3개로 최초로 잡혀 있으며, 화장실을 이용할때마다 -1을 해주고, 나오면 +1 을 해줌. 0이하부터는 기다려야 함
- 세마포어는 뮤텍스 역활도 가능하지만, 뮤텍스는 세마포어가 될 수 없음
threading.Semaphore(10)이런식으로 파이썬에서 코드를 만들어서, 한번에 10개씩 처리 가능 시 큰 차이는.. 뮤텍스의 경우, 뮤텍스를 소유하고 있는 쓰레드만이 뮤텍스를 해제가능 합니다.
마치 볼일 다보고 화장실 키를 다음 사람에게 넘겨야 지만 다음 사람이 이용 가능한 것 처럼요.
반면에 세마포어는 lock key를 소유하지 않고도 세마포어를 해제 할 수 있습니다.
물론 임계값 안에서 실행만 된다고 하면요 :)
3.1 테스트의 종류에 대해서 설명.
- Unit Test: 특정 function, class를 테스트를 하며, 보통 dependency 를 존재하지 않습니다.
- Integration Test: 다중 시스템 안에서, inter-operation이 잘 되는지 테스트
- Smoke Test (Sanity Check): 소프트웨어 빌드 이후 주요 기능이 잘 동작하는지 테스트 (전자 기기에 전원 넣었을때 연기 나는지 테스트에서 유래)
- Regression Test: 버그 픽스 이후에, 동일한 버그가 다시 나오는지 테스트 (원래 이름은 non-regression test임). 또는 뭔가를 수정후 동일한 return을 하는지 체크도 포함
- Canary Test: automated, non-destructive test입니다. 실제 프로덕션 환경에서 주기적으로 작동을 잘 하는지 테스트 합니다.
YAGNI 그리고 KISS 에 대해서 설명
- YAGNI (You ain’t gonna need it): 그냥 오버 애널라이징 또는 엔지니어링 하는 것을 의미함.
클라이언트가 요구한 것 이외의 자신의 요구사항을 넣어서 딜레이 시키거나, 비용을 올려서 전체 프로젝트의 임팩트를 줄이는 행위를 말함 - KISS (Keep it simple stupid): 쉽게 만들면, 관리하기도 쉬워짐. 쉽게 만든다는 뜻이 적게 일한다는 뜻은 절대로 아님. 오히려 더 많은 지식과 경험이 필요함.
4. Security
4.1 Symmetric VS Asymmetric Encryption
- Symmetric Encryption (대칭키)
- Sender와 Receiver는
동일한 키하나로 encrypt 그리고 decrypt 를 합니다. - 공개키 방식에 비해서 속도가 빠릅니다.
- 키를 전달하는 방식에 있어서 문제가 있으며, 전달 도중 탈취될 염려가 있습니다. -> 그래서 공개키가 나옴
- wofish, Serpent, AES, Blowfish, CAST5, RC4, 3DES, SEED
- Sender와 Receiver는
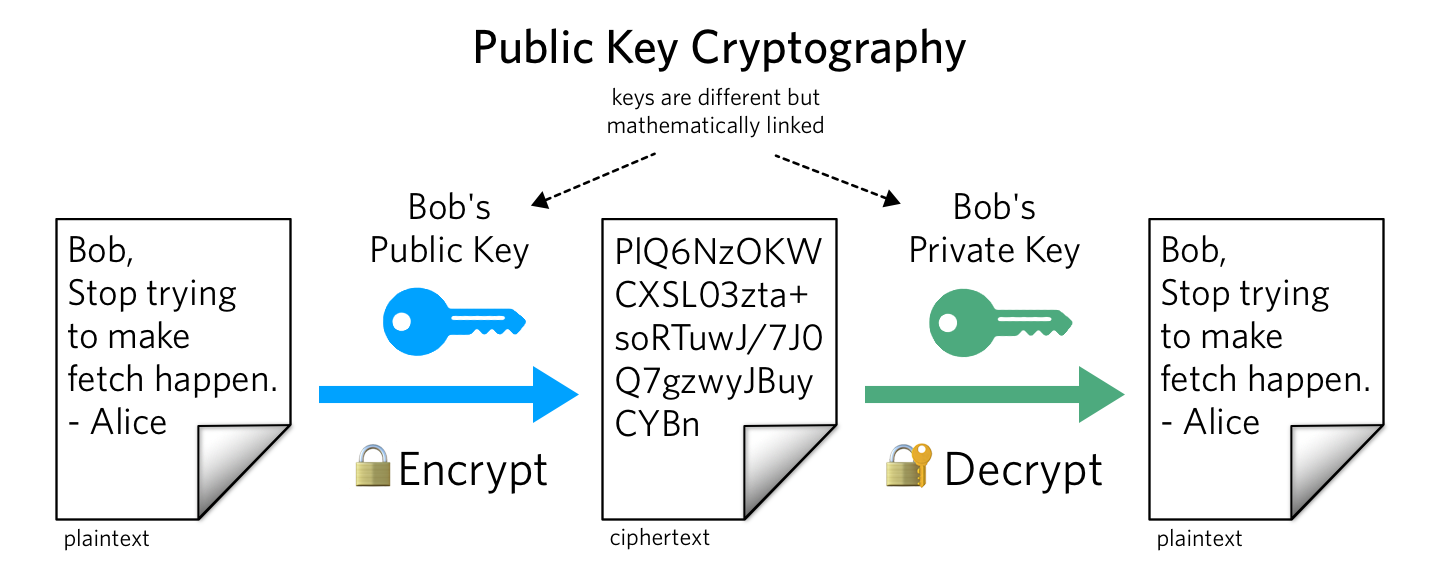
- Asymmetric Encryption (Public Key 공개키 / 비대칭키)
- public key 그리고 private key 두개를 사용합니다.
- public key는 모든 사람이 접근해도 괜찮으며, Sender는 공개키(public key)를 이용해서 encrypt 합니다.
- private key를 갖고 있는 Receiver만 private key로 공개키로 encrypted 된 내용을 볼 수 있습니다.
- 제3자가 Public Key를 갖었다 하더라도, Private키 없이는 Decrypt할 수 없습니다.
- Encryption은 Public Key만 있어도 할 수 있습니다.
- Symmetric Encryption에 비해서 느립니다.
- RSA
4.2 SSL/TLS handshake 방식 설명
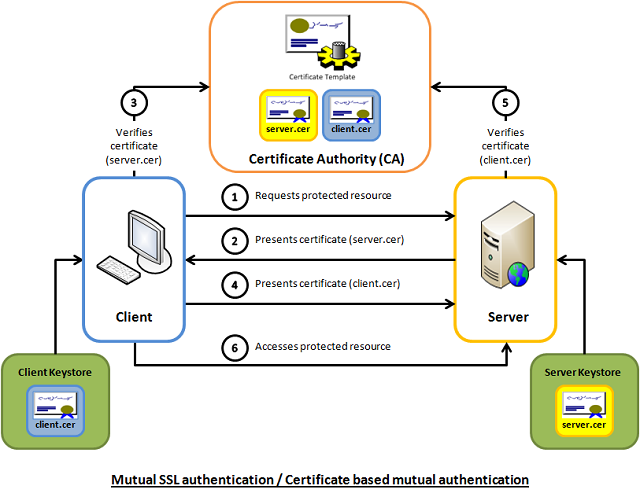
- Client Hello: 클라쪽 SSL버젼 정보, Cipher Suite list (지원하는 암호화 방식), 무작위 바이트 문자열 -> 서버로 보냄
- Server Hello: 암호화 방법 선택 이후 SSL Certificate, 무작위 바이트 문자열 -> 클라로 보냄
- 서버가 보낸 SSL Certificate에는 서버측 public key, 그리고 서비스 정보를 담고 있다
- CA에서 인증: 클라는 서버에서 SSL Certificate을 받았지만, 신뢰할수 있는지 확인하기 위해서 CA에서 확인을 하게 됨
- CA: certificate authority 로서 GeoTrust, IdenTrust를 의미
- 클라는 서버가 전달해준 certificate을 CA로 보버냄
- certificate에서 public key를 꺼내고 CA의 private key를 사용해서 encrypted data를 decrypt함
- decrypt가 잘됐다면 CA에서 인증한 certificate이기 때문에 신뢰함
- 클라는 symmetric session key를 생성하고, 서버가 보내준 certificate에 존재하는 public key로 encrypt 함. -> 그리고 서버로 보냄
- 서버는 private key로 encrypted session key를 decrypt해서, symmetric session key 를 얻음
- 이후! 클라와 서버는 symmetric session key로 서로 encrypt 또는 decrypt하면서 정보를 주고 받음.
4.3 WAF VS Firewall
WAF (Web Applicagtion Firewall 일명 와프) 그리고 일반적인 Firewall의 차이는 다음과 같습니다.
- WAF
Layer 7 (Application Level)계층에서의 방어를 함- 기존 방화벽과는 다르게, packet의 내용(payload)를 검사하여 SQL Injection, Buffer OverFlow (BOF), CSRF 공격 등등 다양한 공격을 검사하여 차단합니다.
- 외부로 유출하면 안되는 주민등록번호, 핸드폰등의 개인정보또한 검출하여 차단할수 있습니다.
- 기존 방화벽은 HTTPS일 경우 암호화 되어 있기 때문에 내용을 볼수가 없지만, Layer 7 에서 방어하는 웹방화벽은 내용을 보고 방어를 할 수 있습니다.
- Firewall
Layer 3 (Network Level)에서 방어를 함- 접근제어: 송/수신자의 IP 주소, 프로토콜 (TCP, UDP), 포트 번호를 기준으로 패킷 필터링을 합니다.