Faster R-CNN
What is Faster R-CNN
Deep learning에 처음 들어온 사람들은 보통 MNIST 데이터를 갖고서 딥러닝으로 손글씨를 인식하는 모델을 만듭니다. 하지만 실제 인간이 접하는 비젼의 문제는 이것보다 훨씬 까다롭습니다. 아래 사진은 뉴욕의 사진입니다. 엄청나게 많은 사람들, 차량, 광고, 건물, 신호등 등등의 복잡한 객체들로 이루어져 있습니다.

인간은 이 복잡한 그림 속에서 대부분을 모두 구분 할 수 있으며, 심지어 겹쳐있는 사물들도 알 수 있고, 사물과 사물의 관계또한 알 수 있습니다. 인공지능이 사물과 사물들을 구분해내고 분류할 수 있을까요? Faster R-CNN을 사용하면 이미지속의 여러 사물을 한꺼번에 분류해 내놓으며, 데이터 학습에 따라서 겹쳐 있는 부분들 까지도 정확하게 사물들을 분류해낼 수 있습니다.

여러가지 알고리즘들이 있습니다. R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN, YOLO, YOLO v2 등등.. 최초가 된 분석 방법은 R-CNN이고, selective search의 단점을 보완한게 Fast R-CNN이고, 여기서 다시 보완한게 Faster R-CNN입니다. YOLO의 경우 속도가 Faster R-CNN보다 훨씬 빠릅니다만 예측률이 떨어집니다. YOLO가 초당 50장정도 처리 가능하다고 하면, Faster R-CNN의 경우 5~7장정도밖에 처리를 하지 못합니다. Faster R-CNN과 YOLO의 차이는 예측률과 속도 사이의 trade off를 선택하는 것 입니다.
Architecture
Introduction
Faster R-CNN은 두개의 네트워크로 구성이 되어 있습니다.
- Deep Convolution Network로서 Region Proposal Network (RPN) 이라고 함
- Fast R-CNN Detector로서 앞의 proposed regions을 사용하여 object를 감지함
Faster R-CNN안에는 2개의 모듈이 존재하지만, 전체적으로는 하나의 object detection network라고 볼 수 있습니다. 이게 중요한 이유는 Fater R-CNN이후부터 fully differentiable model이기 때문입니다.
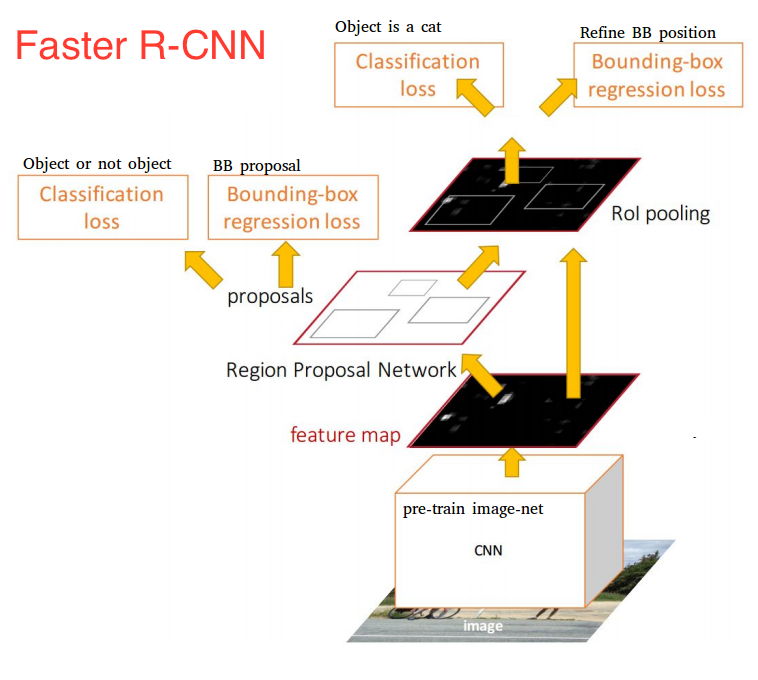
가장 상위단서부터 큰 그림을 그리면서 세부적인 부분을 설명하도록 하겠습니다.
Input Images
Input images는 Height x Width x Depth 를 갖고 있는 tensors입니다. 쉽게 말해 그냥 RGB컬러를 갖고 있는 이미지입니다.
Base Network (Shared Network)
Name Meaning
일단 이름의 의미부터 보도록 하겠습니다. 이전 R-CNN에서는 Region proposal을 하기 위해서 selective search를 사용했습니다. Selective search를 통해서 나온 수천개 각각의 region proposals마다 CNN(AlexNet)을 사용하여 forward pass를 하였습니다. 또한 3개의 모델(feature를 뽑아내는 CNN, 어떤 class인지 알아내는 classifier, bounding boxes를 예측하는 regression model)을 각각 학습시켜야 했습니다.
Fast R-CNN에서는 중복되는 연산을 하나의 CNN 으로 해결을 해버립니다. 즉 이미지를 가장 먼저 받아서 feature를 뽑아내는 일을 하기 때문에 base network 또는 중복되는 일을 하나의 CNN에서 처리하기 때문에 shared network라고 하는 것 입니다. 자세한 내용은 CNN 히스토리 또는 Fast R-CNN과 Faster R-CNN의 비교를 참고합니다.
How it works
Base network 가 하는 일은 이미지에 대한 features extraction입니다. 중요한 포인트는 사실 이미 학습이 되어 있는 모델(pre-trained model)을 사용해야 한다는 것 입니다. (즉 transfer learning과 유사하며 CNN의 특징을 알고 있다면 왜 이렇게 하는지 이해가 될 겁니다.)
모델은 기존의 모델을 주로 사용합니다. ResNet, VGG, Google의 Inception등등 다양하게 사용할 수 있습니다. 다만 찾고자 하는 object의 feature를 뽑아내야 하기 때문에 이미 해당 object를 학습해 놓은 상태여야 합니다. 아래와 같이 이미지를 input값으로 받아서 CNN모델에 들어가게 되면 output으로 찾고자 하는 object의 feature maps 을 얻을 수 있습니다.

Region Proposal Networks
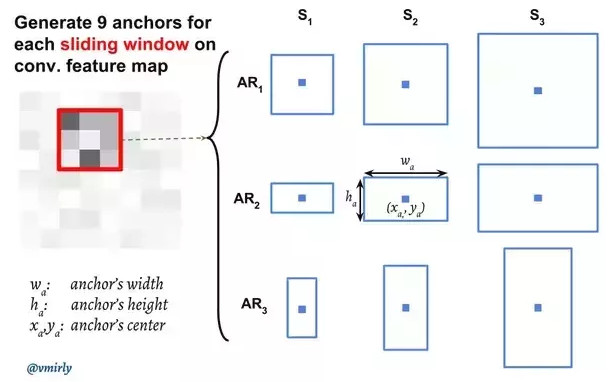
Region Proposal Network (RPN)은 convolution을 사용하여 구현이 되며, input 값은 이전 base network에서 뽑아낸 feature maps을 사용합니다. Region proposals을 생성하기 위해서는 base network에서 생성한 feature maps위에 n x n spatial window (보통 3 x 3)를 슬라이드 시킵니다. 각각의 sliding-window가 찍은 지점마다, 한번에 여러개의 region proposals을 예측하게 됩니다. Region proposals의 최고 갯수는 \(k\) 로 나타내며, 이것을 Anchor 라고 부릅니다. 보통 각 sliding window의 지점마다 9개의 anchors가 존재하며 , 3개의 서로 다른 종횡비 (aspect ratios) 그리고 3개의 서로 다른 크기(scales) 가 조합되며 모두 동일한 중앙 지점 \((x_a, y_a)\) 을 갖고 있습니다.
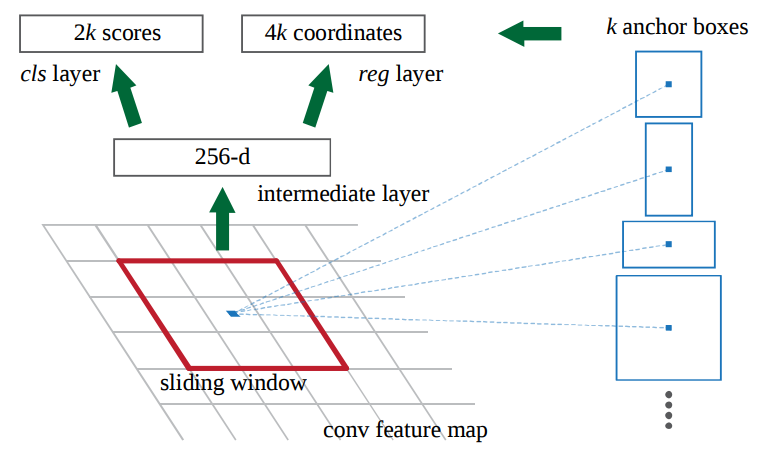
Sliding window를 통해서 나온 feature map의 depth는 더 낮은 차원이 됩니다. (예. 512 depth –> 256 depth) 이후의 output값은 1 x 1 kernel을 갖고 있는 두개의 convolutional layers로 양분되어 들어가게 됩니다.
Classification layer에서는 anchor당 2개의 predictions값을 내놓으며, 객체인지 아니면 객체가 아닌지(그냥 배경인지)에 관한 확률값입니다.
Regression layer (또는 bounding box adjustment layer)는 각 anchor당 델타값들 \(\Delta_{x_{\text{center}}}\), \(\Delta_{y_{\text{center}}}\), \(\Delta_{\text{width}}\), \(\Delta_{\text{height}}\) 4개의 값을 내놓습니다. 이 델타 값들은 anchors에 적용이 되어서 최종 proposals을 얻게 됩니다.
Classifier of Background and Foreground
Classifier를 학습시키기 위한 training data는 바로 위의 RPN으로 부터 얻은 anchors 와 ground-truth boxes (실제 사람이 직접 박스 처리한 데이터) 입니다.
모든 anchors를 foreground 이냐 또는 background이냐로 분류를 해야 합니다. 분류를 하는 기준은 어떤 anchor가 ground-truth box와 오버랩 (중복되는 면적)되는 부분이 크면 foreground이고, 적으면 background입니다. 각각의 anchor마다 foreground인지 아니면 background인지 구별하는 값을 \(p^*\) 값이라고 했을때 구체적인 공식은 다음과 같습니다.
\[\begin{equation} p^* = \begin{cases} 1 & \text{if } IoU \gt 0.7 \\ -1 & \text{if } IoU \lt 0.3 \\ 0 & \text{if otherwise} \end{cases} \end{equation}\]여기서 IoU는 Intersection over Union으로서 다음과 같이 정의가 됩니다. 자세한 내용은 여기 를 참고 합니다.
\[\begin{equation} IoU = \frac{\text{anchor } \cap \text{ ground-truth box}}{\text{anchor } \cup \text{ ground-truth box}} \end{equation}\]일반적으로 IoU값이 가장 높은 값을 1값으로 잡으면 되지만.. 정말 레어한 케이스에서 잘 잡히지 않는 경우 0.7이상으로 해서 잡으면 됩니다. 또한 하나의 ground-truth box는 여러개의 anchors에 anchors에 1값을 줄 수 가 있습니다. 또한 0.3 이하의 값으로 떨어지는 anchor는 -1값을 줍니다. 그외 IoU 값이 높지도 정확하게 낮지도 않은 anchors들 같은 경우는 학습시 사용되지 않는… 그냥 아무취급도 안하면 됩니다. (태스크에 따라서 0.7이상이냐 0.3이하냐는 언제든지 바뀔 수 있습니다.)
Bounding Box Regression
Bounding box regression에는 4개의 좌표값을 사용합니다. \(t\) 라는 값 자체가 4개의 좌표값을 갖고 있는 하나의 벡터라고 보면 되며 다음과 같은 엘러먼트 값을 갖고 있습니다.
\[\begin{align} t_x &= (x - x_a) / w_a \\ t_y &= (y - y_a) / h_a \\ t_w &= \log(w/w_a) \\ t_h &= \log(h/h_a) \end{align}\]ground-truth vector \(t^*\) 에는 위와 유사하게 다음과 같은 값을 갖고 있습니다.
\[\begin{align} t^*_x &= (x^* - x_a) / w_a \\ t^*_y &= (y^* - y_a) / h_a \\ t^*_w &= \log(w^*/w_a) \\ t^*_h &= \log(h^*/h_a) \end{align}\]- \(t_x, t_y\) : 박스의 center coordinates
- \(t_w, t_h\) : 박스의 width, height
- \(x, y, w, h\) : predicted box
- \(x_a, y_a, w_a, h_a\) : anchor box
- \(x^*, y^*, w^*, h^*\) : ground-truth box
Region of Interest Pooling
RPN이후, 서로 다른 크기의 proposed regions값을 output으로 받습니다. 서로 다른 크기라는 말은 CNN에서 output으로 나온 feature maps또는 제각각 다른 크기라는 뜻입니다. 특히 일반적으로 feature maps을 flatten시켜서 딥러닝을 태워서 추후 classification을 할때는 더더욱 어렵게 됩니다.
이때 사용하는 기법이 Region of Interest Pooling(ROI) 기법입니다. ROI를 사용하게 되면 서로 다른 크기의 feature maps을 동일한 크기로 변환시켜줄수 있습니다.
How it works
아래의 내용은 링크에서 참고하였습니다.
ROI를 구현하기 위해서는 다음의 2개의 inputs이 필요합니다.
- Deep convolutions 그리고 max pooling layers를 통해 나온 feature map
- N x 4 매트릭스 -> N은 RoI의 갯수, 4는 region의 위치를 나타내는 coordinates
아래의 그림은 region proposals (핑크 직사각형) 이 포함된 이미지 입니다.

ROI 가 로직은 다음과 같습니다.
- 각각의 region proposal을 동일한 크기의 sections으로 나눕니다. (section의 크기는 RoI pooling의 output크기가 동일합니다.)
- 각각의 section마다 가장 큰 값을 찾습니다.
- 각각의 찾은 maximum값을 output 으로 만듭니다.
Region of Interest Pooling Example
링크에서 가져온 내용입니다.
예를 들어서 8 x 8 형태의 feature map을 다음과 같이 있다고 가정합니다.
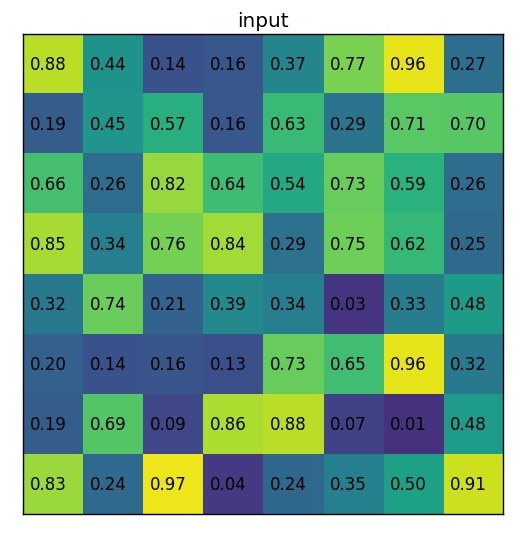
Region proposal의 값은 (0, 3), (7, 8) 일때 다음과 같습니다.
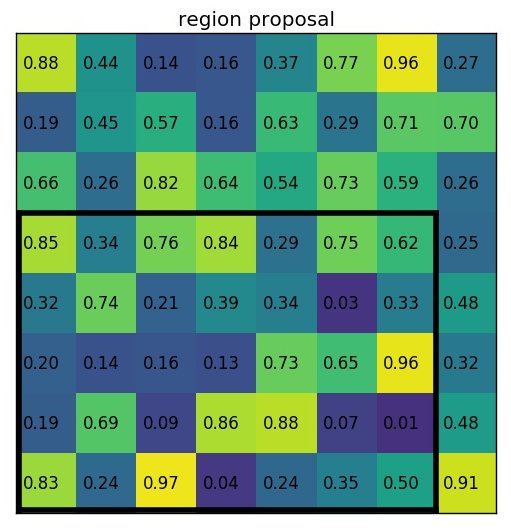
실제로는 수십~수천장의 feature maps을 갖고 있겠지만, 예제에서는 문제를 간단하게 하기 위해서 1개의 feature map만 있다고 가정을 합니다.
Section의 크기 2 x 2 로 region proposal을 아래와 같이 나눕니다.
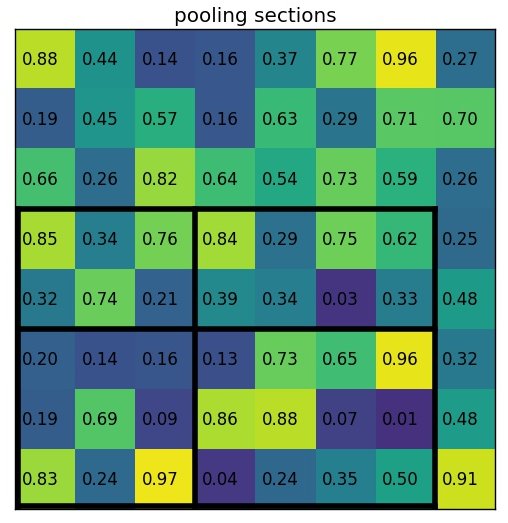
위에서 보다시피 section의 크기는 모두 동일할 필요는 없습니다. 다만 크기가 거의 동일하기만 하면 됩니다.
Max values를 끄집어 내면 다음과 같은 output이 생성이 됩니다.
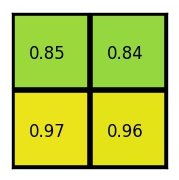
물론 Region of Interest Pooling을 사용할수도 있지만 아래쪽에 더 쉽게 구현 가능한 방법을 아래에 “Fixed-size Resize instead of ROI Pooling” 이름으로 정리해놨습니다.
Training
Loss Function
\[L(\{p_i\}, \{t_i\}) = \frac{1}{N_{cls}} \sum_i L_{cls} (p_i, p^*_i) + \lambda \frac{1}{N_{reg}} \sum_i p^*_i L_{reg} (t_i, t^*_i)\]- \(i\) : mini-batch 안에서의 anchor의 index
- \(p_i\) : anchor \(i\) 가 객체인지 배경인지의 예측값
- \(p^*_i\) : ground-truth label 로서 1이면 해당 anchor가 positive(객체)라는 뜻이고, 0이면 negative(배경)
- \(t_i\) : 4개의 bounding box의 값을 갖고 있는 벡터
- \(t^*_i\) : ground-truth box 로서 positive anchor와 관련되어 있다.
- \(L_{cls}\) : log loss (object 냐 또는 아냐냐.. 두 클래스간의 손실 함수)
- \(L_{reg}\) : smooth l1 loss function (오직 positive anchors \(p^*_i = 1\) 에만 사용됨.)
- \(N_{cls}\) : normalization. mini-batch 크기와 동일 (i.e. \(N_{cls} = 256\) )
- \(N_{reg}\) : normalization. anchor locations의 갯수와 동일 (i.e. \(N_{reg} \sim 2400\) )
- \(\lambda\) : 기본값으로 10 (목표는 cls 그리고 reg 둘다 거의 동등하게 가중치를 갖도록. 이 값에 따라서 학습의 결과가 매우 달라질수 있다.)
\(N_{reg}\) 는 Smooth L1 function의 공식을 사용합니다. Smooth L1의 경우 L1과 동일하지만, error의 값이 충분히 작을 경우 거의 맞는 것으로 판단하며, loss값은 더 빠른 속도로 줄어들게 됩니다.
\[\text{smooth}_{L1}(x) = \begin{cases} 0.5 x^2 & \text{if } |x| \lt 1 \\ |x| - 0.5 & \text{otherwise} \end{cases}\]Training RPN
하나의 이미지에서 random 으로 256개(batch 크기)의 anchors를 샘플링합니다. 이때 positive anchors(객체)와 negative anchors(배경)의 비율은 1:1이 되도록 합니다. 만약 그냥 랜덤으로 진행시, negative anchors의 갯수가 더 많기 때문에 학습은 어느 한쪽으로 편향되게 학습이 될 것입니다.
하지만 현실적으로 1:1 비율을 지속적으로 유지시키는 것은 매우 어렵습니다. 대부분의 경우 positive samples의 갯수가 128개를 넘지 못하는 경우인데, 이 경우 zero-padding을 시켜주거나, 아예 없는 경우는 IoU값이 가장 높은 값을 사용하기도 합니다.
페이퍼에서는 추가되는 새로운 레이어의 weights값은 0 mean, 0.01 standard deviation을 갖고 있는 gaussian distribution으로 부터 초기화를 합니다 (BaseNet 에 해당되는 ImageNet 을 제외, 즉 pre-trained model을 사용하기 때문에). Learning rate의 경우 처음 60k mini-batches에 대해서는 0.001, 그 다음 20k mini-batches에 대해서는 0.0001을 PASCAL VOC dataset에 적용을 합니다.
Processing Tips
Non-Maximum Suppression
Faster R-CNN에 대한 학습이 완료된 후, RPN 모델을 예측시키면 아마도 한 객체당 여러개의 proposals (bounding boxes) 값을 얻을 것 입니다. 이유는 anchors자체가 어떤 객체에 중복이 되기 때문에 proposals 또한 여러개가 되는 것 입니다.
문제를 해결하기 위해서 non-maximum suppression (NMS) 알고리즘을 사용해서 proposals의 갯수를 줄이도록 합니다. NMS를 간단히 설명하면 먼저 IoU값으로 proposals을 모두 정렬시켜놓은뒤, RoI점수가 가장 높은 proposal과 다른 proposals에 대해서 overlapping을 비교한뒤 overlapping이 높은 것은 특정 threshold이상이면 지워버리며 이 과정을 iterate돌면서 삭제시킵니다.
직관적으로 설명하면 RoI가 높은 bounding box가 있는데.. 이 놈하고 overlapping 되는 녀석들중 특정 threshold이상이면 proposals에서 삭제시켜버리는 형태입니다. 그러면 서로 오버랩은 되지 않으면서 RoI가 높은 녀석들만 남게 됩니다.
일반적으로 threshold의 값은 0.6~0.9 정도로 합니다.

NMS 는 training시에도 학습 속도를 높이기 위해서 사용 할 수 있습니다.
ROI-Removed Model
만약 구분해야 될 클래스가 1개밖에 없을때는 RPN만 사용해서 구현이 가능합니다. 객체인지 아니면 배경인지를 구분하는 classifier자체를 사용해서 클래스를 구별해주면 됩니다.
비젼에서 가장 대표적인 예가 face detection 그리고 text detection등이 있습니다. RPN만 사용하게 됨으로 당연히 training 그리고 inference의 속도는 매우 빨라지게 됩니다.
Fixed-size Resize instead of ROI Pooling
Region of Interest Pooling 대신 object detection을 실제 구현할때 그냥 더 많이 쓰이고 쉬운 방법이 있습니다. 각각의 convolutional feature map을 각각의 proposal로 crop을 시킨뒤에, copped된 이미지를 고정된 크기 14 x 14 x depth 로 interpolation (보통 bilinear)을 사용하여 resize 시킵니다. 이후 2 x 2 kernel을 사용하여 7 x 7 x depth 형태의 feature map으로 max pooling시켜줍니다.
위에서 사용된 크기나 값들은 그 다음에 사용될 block (보통 fully-connected dense layer)에 따라서 결정됨으로 다양하게 바뀔수 있습니다.