Stock Market Prediction

Stock Market Prediction
과거 38일의 데이터를 본후, 그 다음날 (즉 39일째 되느날)의 종가 가격을 예측합니다.
Github Code
를 누르면 전체 소스코드를 확인할 수 있습니다.
Data
S&P 500 (^GSPC)
에서 1950/01/01 부터 07/07/2017년까지의 데이터를 받았습니다.
38일간의 시작가, 종가, 최고가, 최저가, 가격의 데이터를 받아서, 39일이 되는.. 즉 다음날의 종가를 예측합니다.
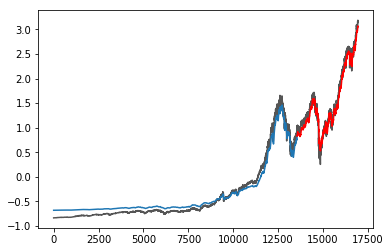
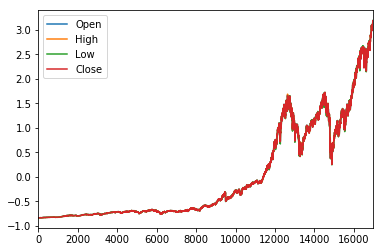
전체 데이터는 다음과 같은 그래프를 그립니다.
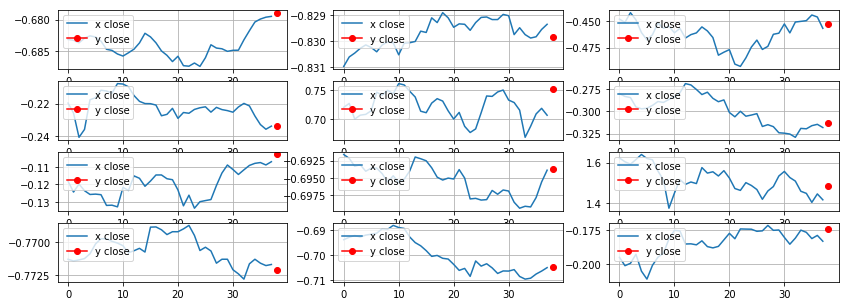
아래 그래프와 같이 과거 38일의 데이터를 본후(파란색선), 다음날의 종가 (빨간점)을 예측합니다.
Model 그리고 Training
모델은 아래와 같이 일반적인 Deep Learning구조를 갖고 있습니다.
중요한 부분은 얼마만큼 overfitting을 일으키지 않도록 구조화되어 있느냐를 잘 보면 됩니다.
def create_model():
model = Sequential()
model.add(Dense(512, kernel_regularizer=l2(0.0001), batch_input_shape=(None, BATCH_SIZE*5)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.6))
model.add(Dense(384, kernel_regularizer=l2(0.0001)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.6))
model.add(Dense(256, kernel_regularizer=l2(0.0001)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.6))
model.add(Dense(128, kernel_regularizer=l2(0.0001)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.6))
model.add(Dense(64, kernel_regularizer=l2(0.0001)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.6))
model.add(Dense(1))
model.add(Activation('linear'))
model.compile(loss='mean_squared_error', optimizer='adam', metrics=[mean_squared_error])
return modelTraining
Training에서는 최소 몇번의 epoch를 돌린뒤, Keras에서 제공하는 EarlyStopping을 사용합니다.
class CustomEarlyStopping(EarlyStopping):
def __init__(self, *args, min_epoch=0, **kwargs):
super(CustomEarlyStopping, self).__init__(*args, **kwargs)
self.min_epoch = min_epoch
def on_epoch_end(self, epoch, logs=None):
if epoch <= self.min_epoch:
return
super(CustomEarlyStopping, self).on_epoch_end(epoch, logs)
early_stopping = CustomEarlyStopping('val_mean_squared_error',
min_epoch=13,
min_delta=0.06,
patience=0)
history = model.fit(train_x, train_y,
verbose=2,
epochs=20,
validation_data=(test_x, test_y),
callbacks=[early_stopping])EarlyStopping 클래스는 다음과 같이 설정할 수 있습니다.
| Argument | Description | Example |
|---|---|---|
| monitor | 측정한 변수 이름. history.history dictionary안의 key값을 보면 됨 |
‘val_loss’, ‘val_mean_squared_error’ |
| min_delta | 측정하는 값이 이하로 떨어지면, 더이상 학습효과가 없다고 판단하며 중단함 | 0, 0.0025 |
| patience | 측정하는 값이 떨어지지 않고 (또는 오히려 loss값이 커질때) 몇번의 epoch를 더 진행할지 설정 | 0, 1 |
| mode | ‘min’, ‘max’, ‘auto’ 3가지중에 선택가능하며.. min은 떨어지지 않을때 중단하며, max는 증가하지 않을때 중단, auto는 측정하려는 값의 이름을 보고 min으로 할지 max할지 자동으로 결정 |
‘min’, ‘max’, ‘auto’ |
| verbose | 0 , 1, 2 |
결과
TRAIN r^2 score: 0.959102586953
TRAIN MSE score: 0.0107864570781
TEST r^2 score: 0.970326221792
TEST MSE score: 0.0120543421595파란선은 training 데이터로부터 예측할 결과물이고, 빨간색선은 test데이터로부터 예측된 결과값입니다.