Cohort Analysis - Retention
Cohort Retention
- Cohort : 비슷한 특성을 가진 그룹을 의미하며 보통 특정 그룹의 유저를 의미함
- Cohort Analysis
- 이탈률 분석 (Churn Analysis): 코호트별 이탈률을 비교하며, 특정 기간동안 신규고객이나 기존 고객이 얼마나 잔존하는지를 파악
- 잔존률 분석 (Retention Analysis): 시간에 따른 코호트별 잔존율을 계산하여, 고객의 유지율을 파악
- 고객 가치 분석 (Customer Lifetime Value Analysis): 코호트별로 고객의 가치를 평가하여 어떤 그룹이 가장 가치 있는지 비교
- 구매 패턴 분석 (Purchases Pattern Analysis) 시간에 따른 코호트별 구매 횟수, 평균 구매액, 반복 구매 등을 분석 하여 고객의 구매 행태를 이해
- 사용자 활동 분석 (User Engagement Analysis) : 코호트별로 사용자들의 활동 수준을 비교하여 어떤 그룹이 참여율이 더 높은지 보여줌
- 유입 채널 분석 (Acquisition Channel Analysis): 코호트의 다양한 유입 경로와 채널을 분석 / 어떤 채널이 가장 효과적인지 판단
- 특정 이벤트 분석 (Event-Based Analysis): 특정 이벤트 (캠페인 / 마케팅) 발생후 코호트의 행동 변화를 관찰
해당 문서에서는 잔존률 분석인 Cohort Retention Analysis 를 계산하는 방법을 적습니다.
Pandas Implementation
Data
데이터는 https://archive.ics.uci.edu/dataset/352/online+retail 에서 다운로드 받습니다.
아래와 같이 데이터를 만듭니다.
import pandas as pd
def prepare_parquet_data():
data_path = r"/home/anderson/Downloads/online-retail.xlsx"
data = pd.read_excel(data_path)
data = data[~data.CustomerID.isna()]
data = data.astype(
{
"InvoiceNo": "string",
"StockCode": "string",
"Description": "string",
"CustomerID": "int64",
"Country": "string",
}
)
data.to_parquet("./data/online-retail.parquet")
# prepare_parquet_data()
data = pd.read_parquet("./data/online-retail.parquet")
data.head()

Cohort Retention
- 필요한 데이터
- Customer ID
- 특정 이벤트 날짜 (결제, 글쓰기, 로그인 등등.. 여기서는 결제 기준)
- Cohort Retention 을 생성하는 방법
- CohortWeek / CohortDay / CohortMonth: 결제 이벤트가 일어난 시점에서 첫번째 날짜로 변경이 필요합니다.
- 예를 들어서 2023-07-03 에 매출이 일어났다면 -> CohortMonth 는 2023-07-01, CohortWeek 29가 됩니다. (1년중에 몇번째 주)
- CohortFirst
- 해당 row에 해당하는 유저가 가장 처음 결제한 날짜입니다.
- FIRST(purchase_date) OVER (PARTITOIN BY USER_ID) 이것과 유사합니다.
- 테이블 row 마다 해당 customer ID가 있을텐데, 해당 유저의 첫번째 결제일을 집어넣습니다.
- CohortFirst는 Cohort Retention 에서 테이블의 Y축에 해당하게 됩니다.
- CohortIndex 생성
- 처음결제한 날 - 특정일에 결제 한 날 -> 차이를 구해서 Index를 생성합니다.
- FirstPurchaseDate - PurchaseDate ->
- 예를 들어 1 이면 하루차이, 3이면 3일 이후, 10 이면 10일 이후 이런 식 입니다.
- 해당 Index는 Cohort Retention 에서 X 축에 해당하게 됩니다.
- 즉 맨 좌측이 처음 결제한 날짜 -> 우측으로 갈수록 그 이후의 날짜들.
- CohortWeek / CohortDay / CohortMonth: 결제 이벤트가 일어난 시점에서 첫번째 날짜로 변경이 필요합니다.
from datetime import date, datetime, timedelta
def iso_year_start(iso_year):
"The gregorian calendar date of the first day of the given ISO year"
fourth_jan = date(iso_year, 1, 4)
delta = timedelta(fourth_jan.isoweekday() - 1)
return fourth_jan - delta
def iso_to_gregorian(iso_year, iso_week, iso_day):
"Gregorian calendar date for the given ISO year, week and day"
year_start = iso_year_start(iso_year)
return year_start + timedelta(days=iso_day - 1, weeks=iso_week - 1)
def calculate_weekly_retention(data, costomer_col, date_col):
# CohortWeek: 기준이 되는 year + week of the year 사용
# CohortFirstWeek: 해당 고객의 가장 처음 구매한 Invoice 날짜를 넣음.
# transform 은 min(CohortWeek) OVER (PARTITOIN BY customer) 와 유사 -> 동일한 index shape 을 리턴
# CohortIndex: 거래한 날짜 - 처음 거래한 날자 => 이렇게 하면 1주전, 2주전, 3주전, 4주전 등등 처럼 언제 구매했었는지 나타낼수 있다
data["CohortWeek"] = data[date_col].apply(lambda x: iso_to_gregorian(x.year, x.week, 1))
data["CohortFirstWeek"] = data.groupby(costomer_col).CohortWeek.transform("min")
data["CohortIndex"] = (data.CohortWeek - data.CohortFirstWeek).dt.days
retention = (
data.groupby(["CohortFirstWeek", "CohortIndex"])
[costomer_col].apply(pd.Series.nunique)
.reset_index()
)
retention_count = retention.pivot_table(index="CohortFirstWeek", columns="CohortIndex", values=costomer_col)
retention = retention_count.divide(retention_count.iloc[:, 0], axis=0).round(3)
return retention_count, retention
retention_count, retention = calculate_weekly_retention(
data[data.InvoiceDate.dt.year != 2009], costomer_col="CustomerID", date_col="InvoiceDate"
)
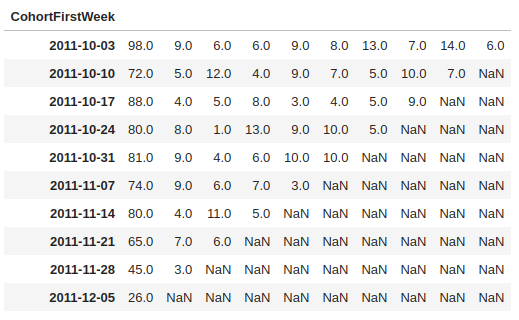
retention_count 테이블은 다음과 같이 생겼습니다.
- 2011-10-03 의 인사이트는 다음과 같습니다.
- 해당일에 처음 결제한 유저는 98명 입니다.
- 일주일 뒤에 동일한 유저가 결제한 유저는 9명 입니다.
- 이주일뒤에 그 동일한 유저가 결제한 유저는 6명 입니다.
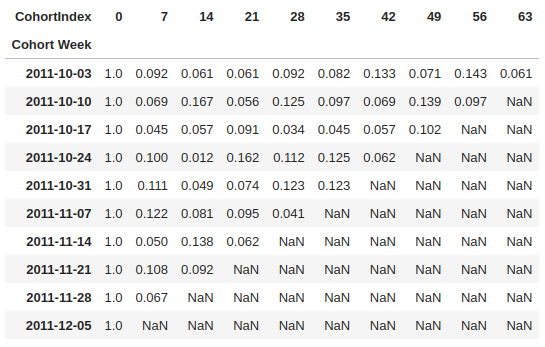
retention 테이블은 다음과 같이 생겼습니다.
확률로 변환 된 것입니다.
- 2011-10-03 의 인사이트는 다음과 같습니다.
- 첫날이니까.. 당연히 100% 이겠죠.
- 일주일뒤 9.2% 가 재구매 했습니다.
- 2주일뒤에 6.1% 가 재구매 했습니다.
- 42일뒤를 보니까, 무슨일이 있었나 보네요. 갑자기 13.3%로 오릅니다.
- 63일뒤를 보니까, 6.1% 로 다시 줄어들었습니다.
- 즉.. 대략 처음 구매 이후에 대략 6 ~ 10%가 꾸준하게 구매를 하는 듯 합니다.
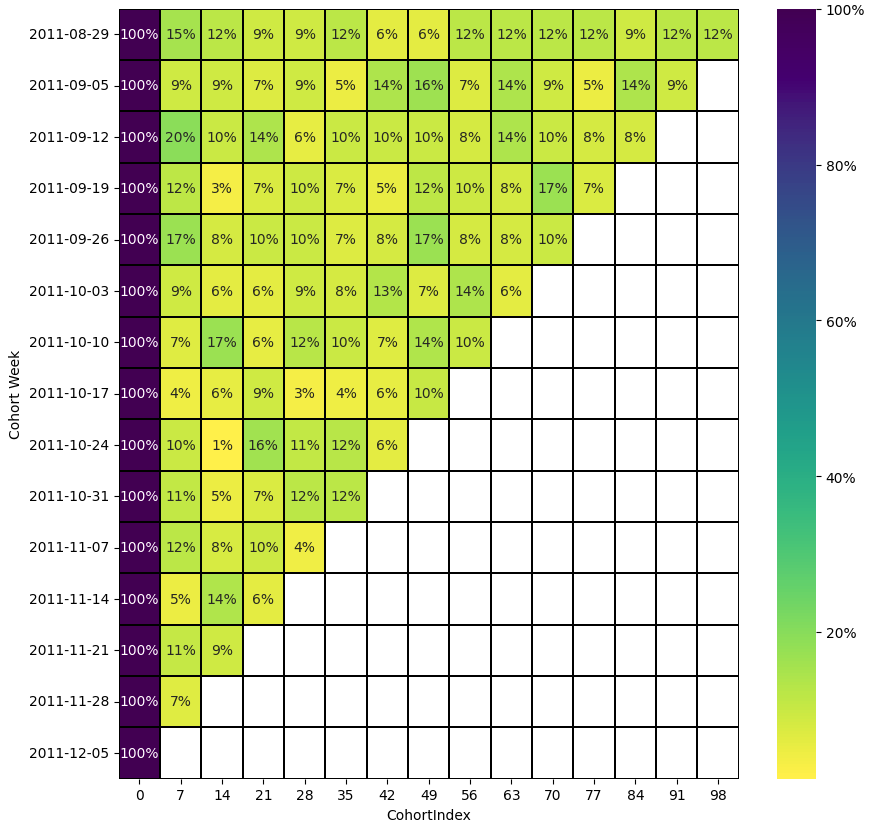
Heatmap
좀 더 잘 표현하기 위해서 다음과 같이 heatmap 으로 표현 가능합니다.
import matplotlib.ticker as ticker
plt.subplots(1, figsize=(10, 10))
ax = sns.heatmap(
retention.iloc[-15:, :15],
cmap="viridis_r",
linewidths=0.2,
linecolor="black",
annot=True,
fmt=".0%",
cbar_kws={"format": ticker.FuncFormatter(lambda y, _: f"{y :0.0%}")},
)
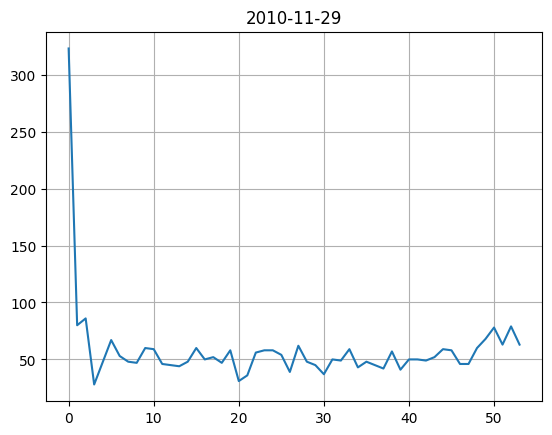
line plot
특정 날짜만을 보고 싶으면 다음과 같이 할수도 있습니다.
df = retention_count[pd.to_datetime(retention_count.index) == '2010-11-29']
ax = sns.lineplot(df.values.reshape(-1))
ax.set_title('2010-11-29')
ax.grid()
Daily Retention
- 일별로 유저를 추적하면, 그 그룹양이 적다.
from datetime import date, datetime, timedelta
def calculate_daily_retention(data, costomer_col, date_col):
data["CohortDay"] = data[date_col].apply(lambda x: x.date())
data["CohortFirstDay"] = data.groupby(costomer_col).CohortDay.transform("min")
data["CohortIndex"] = (data.CohortDay - data.CohortFirstDay).dt.days
retention = (
data.groupby(["CohortFirstDay", "CohortIndex"])
[costomer_col].apply(pd.Series.nunique)
.reset_index()
)
retention_count = retention.pivot_table(index="CohortFirstDay", columns="CohortIndex", values=costomer_col)
retention = retention_count.divide(retention_count.iloc[:, 0], axis=0).round(3)
return retention_count, retention
retention_count, retention = calculate_daily_retention(
data, costomer_col="CustomerID", date_col="InvoiceDate"
)
display(retention.iloc[-10:, :10])
display(retention_count.iloc[-10:, :10])