Amazon Kinesis Data Streams
1. Introduction
1.1 Architecture
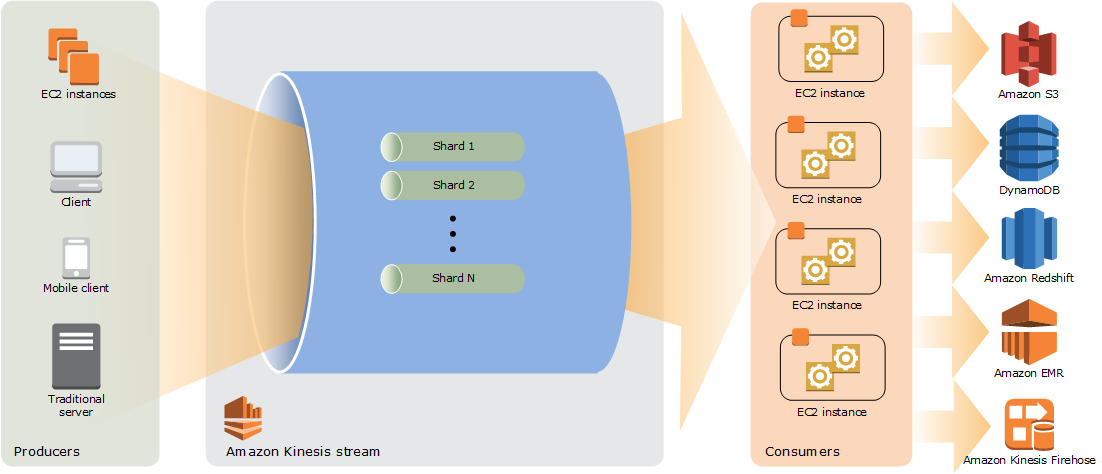
- Kinesis는 Shards로 이루어져 있음
- Data Record: Kinesis안에서 일종의 데이터 유닛이며, sequence number 그리고 Partition Key 으로 구성
- Retention Period: 기본값 24시간이고, 7일까지 늘릴수 있음
- Producer & Consumer: 보내고 받는 받는 쪽이고, Consumer의 경우 Stream Application이라고도 함
- Shard
- Read: 초당 5 transactions, 그리고 2MB 데이터를 읽을 수 있음
- Write: 초당 1000 records 를 1MB 까지 (partition key 포함) write 할 수 있음
- 만약 처리하는 데이터가 증가한다면 Resharding이 필요
- Put Record: (Data, StreamName, PartitionKey) <- Producer는 PUT call을 함으로서 데이터를 올림
- Partition Key: producer에 의해서 제공되며, 여러 Shards에 분배시키기 위해서 사용됨
하면서 알게된 중요 포인트
- Consuming from multiple shards
- 만약 Stream안에 여러개의 shards에 있을 경우 Producer는 partition key에 따라서 shard가 배정받고 들어가게 됩니다.
- 즉.. producer 1개에서 -> 다수의 shards로 나뉘어 들어가게 됨.
- Consumer는 이런 다수의 shards로 부터 마치 하나의 stream처럼 데이터를 다운 받을 수 있는가? -> 일단 답은 안됨
- shard 마다 각자 다른 consumer를 정해줘야 함
1.2 Two Types of Consumers
두가지 종류의 Consumers가 존재합니다.
- 그냥 fan-out consumers
- Shard Read Throughput: Shard당 2 MB/sec 고정되어 있으며, 다수의 consumers가 동일한 shard에서 가져갈시(read) 모두 동일한 데이터를 가져가지만, 초당 2MB 을 넘어가면 안됨
- Message Propagation Delay: 하나의 consumer당 200ms 가 걸리고, 5개의 consumers가 존재시 1000ms 까지 느려질수 있음
- Cost: 없음
- enhanced fan-out consumers
- 기존 fan-out consumers의 제약을 넘어서기 위해서 나온 consumer
- Shard Read Throughput: enhanced fan-out consumers는 모두 독립적인 read throughput을 갖으며 각각 2 MB/Sec 를 갖는다
- Message Propagation Delay: 하나의 consumer가 있는 5개가 있든 상관없이 평균 70ms 가 걸림
- Cost: 데이터를 retrival 그리고 consumer-shard hour cost 존재
2. Getting Started
2.1 AWS Kinesis CLI
Put and Get a Record
# Stream 생성
$ aws kinesis create-stream --stream-name Test --shard-count 1
# Stream 정보 얻기
$ aws kinesis describe-stream-summary --stream-name Test
# Put
$ aws kinesis put-record --stream-name Test --partition-key 123 --data testdata
# ShardIterator 얻기
$ aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name Test
{
"ShardIterator": "AAAAAAAAAAEStPmsRs6uXnop71REHTk4zDK+eIVTk2Vl7AI+w6+F6Y2K1UA6igTB6O6SR2ohZBo1YeL971sPIzvR3LQprRDsGd5uFSYJJDsDtUU9NmqPQhyotNToSkV6h4dGyAMH2JY8ULA8rt+lLp/xLPoaLGY7RkUsFBPDN6A6PMnpc01E0tr7zPc5Bam3C2pdm1Rrnu+PcZ9MLInkTURKMza5JYqQ"
}
# 또는 이렇게..
SHARD_ITERATOR=$(aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name Test --query 'ShardIterator')
# Get (ShardIterator값을 복사에서 넣는다)
$ aws kinesis get-records --shard-iterator AAAAAAAAAAEStPmsRs6uXnop71REHTk4zDK+eIVTk2Vl7AI+w6+F6Y2K1UA6igTB6O6SR2ohZBo1YeL971sPIzvR3LQprRDsGd5uFSYJJDsDtUU9NmqPQhyotNToSkV6h4dGyAMH2JY8ULA8rt+lLp/xLPoaLGY7RkUsFBPDN6A6PMnpc01E0tr7zPc5Bam3C2pdm1Rrnu+PcZ9MLInkTURKMza5JYqQ 2.2 IAM Policy and User
아래의 Test Stream에서 ARN을 찾고 복사합니다.
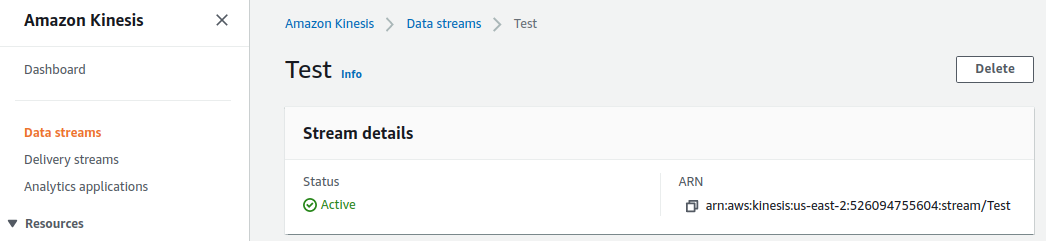
IAM -> Policy -> Create Policy 를 한 후 Service 는 Kinesis 선택하고, 필요한 권한들을 넣습니다.
- DescribeStream
- GetShardIterator
- GetRecords
- PutRecord
- PutRecords
Stream 에다가 TestStream ARN을 넣습니다.
Policy가 만들어지면 User에다가 넣어주면 됩니다.
2.3 Python Code Snippet
아래는 Producer 그리고 Consumer의 Python 예제 입니다.
Producer
import json
import random
from time import sleep
from boto import kinesis as boto_kinesis
from faker import Faker
def generate_data(faker):
return {'name': faker.name(),
'age': random.randint(10, 20),
'gender': random.choice(['M', 'F']),
'score': random.choice(range(40, 70, 5)),
'job': faker.job()}
def main():
faker = Faker()
kinesis = boto_kinesis.connect_to_region('us-east-2')
print('Connected')
if 'AndersonStream' not in kinesis.list_streams()['StreamNames']:
kinesis.create_stream('AndersonStream', 1)
for i in range(50):
data = generate_data(faker)
data['i'] = i
res = kinesis.put_record('AndersonStream', json.dumps(data), 'partitionkey')
print(f'{i:2}', data)
print(' ', res, '\n')Consumer
from boto import kinesis as boto_kinesis
def main():
kinesis = boto_kinesis.connect_to_region('us-east-2')
shard_id = 'shardId-000000000000' # Shard는 1개만 갖고 있음
shard_it = kinesis.get_shard_iterator('AndersonStream', shard_id, 'LATEST')['ShardIterator']
print('Latest Shard Iterator:', shard_it)
while True:
_out = kinesis.get_records(shard_it, limit=10)
records = _out['Records']
for r in records:
print(r['Data'])
shard_it = _out['NextShardIterator']
if not records:
break3. Kinesis Analytics
3.1 Introduction
Amazon Kinesis Data Analytics 는 단순 SQL을 통해서 streaming data를 처리하고 분석하는데 사용할 수 있습니다.
마치 Kafka KSQL과 유사하며, Performance는 떨어지나, 손쉽게 쓰기에는 좋다가 제 생각입니다.
3.2 Continuous Filtering Example
아래 예제에서는 Stream으로 들어오는 데이터에서 “남자”만 뽑아내는 필터를 거는 예제를 보여줍니다.
CREATE OR REPLACE STREAM "AndersonStream" (name VARCHAR(50), age INTEGER, gender VARCHAR(4), score INTEGER, job VARCHAR(50));
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "AndersonStream"
SELECT STREAM "name", "age", "gender", "score", "job"
FROM "SOURCE_SQL_STREAM_001"
WHERE "gender" SIMILAR TO 'M';-- ** Continuous Filter **
-- Performs a continuous filter based on a WHERE condition.
-- .----------. .----------. .----------.
-- | SOURCE | | INSERT | | DESTIN. |
-- Source-->| STREAM |-->| & SELECT |-->| STREAM |-->Destination
-- | | | (PUMP) | | |
-- '----------' '----------' '----------'
-- STREAM (in-application): a continuously updated entity that you can SELECT from and INSERT into like a TABLE
-- PUMP: an entity used to continuously 'SELECT ... FROM' a source STREAM, and INSERT SQL results into an output STREAM
-- Create output stream, which can be used to send to a destination- 먼저 “SOURCE_SQL_STREAM_001” 에서 JSON 데이터가 들어옵니다.
CREATE OR REPLACE STREAM "AndersonStream" ...을 통해서 테이블을 하나 만듭니다. (실시간 처리를 위한 테이블)CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "AndersonStream을 통해서 SOURCE_SQL_STREAM_001 에서 받은 데이터를 AndersonStream 테이블로 넣어주게 됩니다.Where조건문을 통해서 데이터를 발라내게 됩니다.
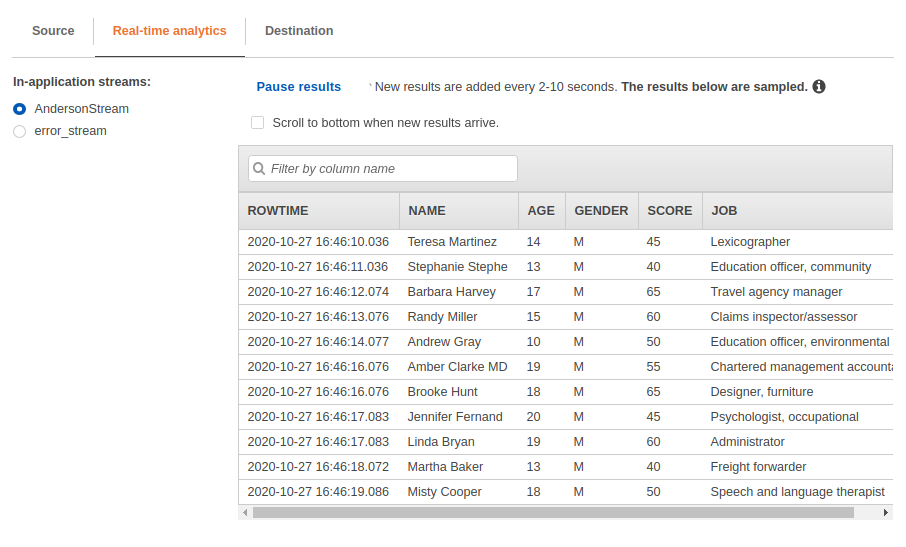
매우 중요한 내용 <쿼리 만들때 매우 중요한 내용입니다.>
- SELECT 문 안쪽에 “name”, “age”, “gender”, “score”, “job” 모두 double quotation을 사용했습니다.
사용 안하면 기본값으로 대문자로 인식하게 되며 single quotation 사용하면 안됩니다. - Where절에서 ‘M’ <– 요 부분이 single quotation으로 사용됐는데.. 이건 또 double quotation사용하면 컬럼으로 인식해서 에러남
Lambda 에 붙여 쓸때 다음과 같이 할 수 있습니다.
Kinesis Analytics에서 Destination을 Lambda로 잡으면 됩니다.
import json
import base64
def lambda_handler(event, context):
output = []
for record in event['records']:
payload = base64.b64decode(record['data'])
output.append(payload)
return {
'output': output
}