Convolutional Neural Networks Part 1
- Convolutional Neural Networks - {:.} What is Convolution? - {:.} What are convolutional Neural Networks? - {:.} The LeNet Architecture (1990s) - {:.} Filter (Sliding Window, Kernel) -> Feature Map (convolved feature, activation map) - {:.} Non Linearity (ReLU) - {:.} The Pooling Step - {:.} Fully Connected Layer - {:.} BackPropagation - {:.} How much deep we need to go? - {:.} Ohter ConvNet Architectures - {:.} References

Convolutional Neural Networks
What is Convolution?
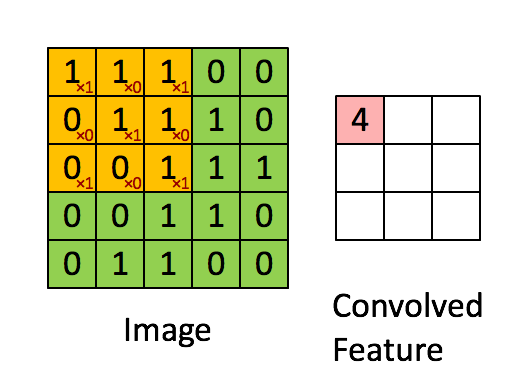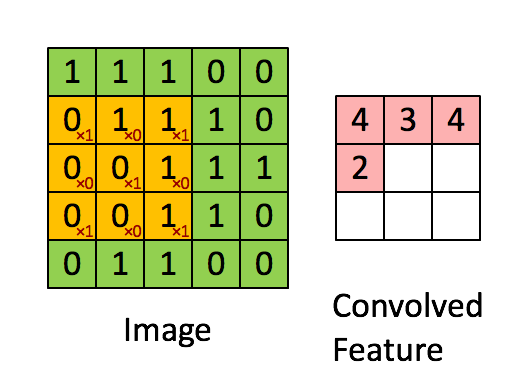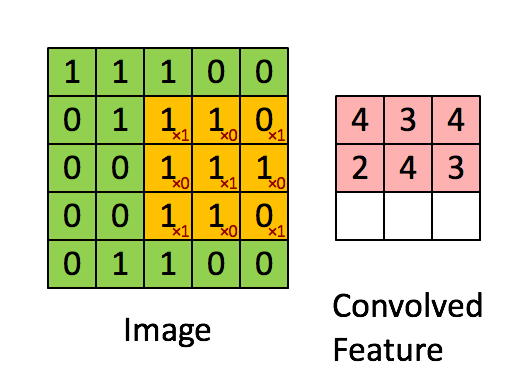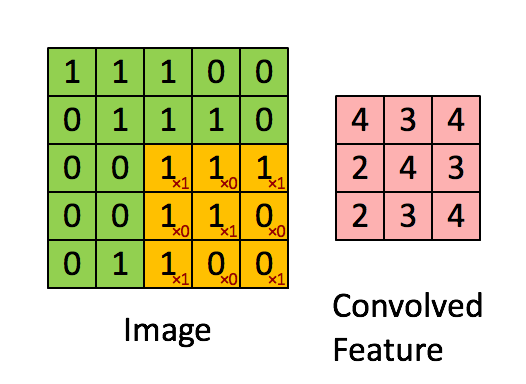
왼족의 matrix를 흑백을 나타내는 이미지라고 합니다. (0은 검정색, 1은 흰색)
3 by 3으로 움직이는 sliding window는 kernel, filter 또는 feature detector 등으로 불립니다.
각각 element-wise 로 곱셉을 해준뒤, 합계를 오른쪽에다 써주게 됩니다.
직관적으로 이해하기 위해서는 Ubuntu의 Gimp를 사용해서 알아볼수 있습니다.
(Gimp -> Filters -> Generic -> Convolution Matrix)
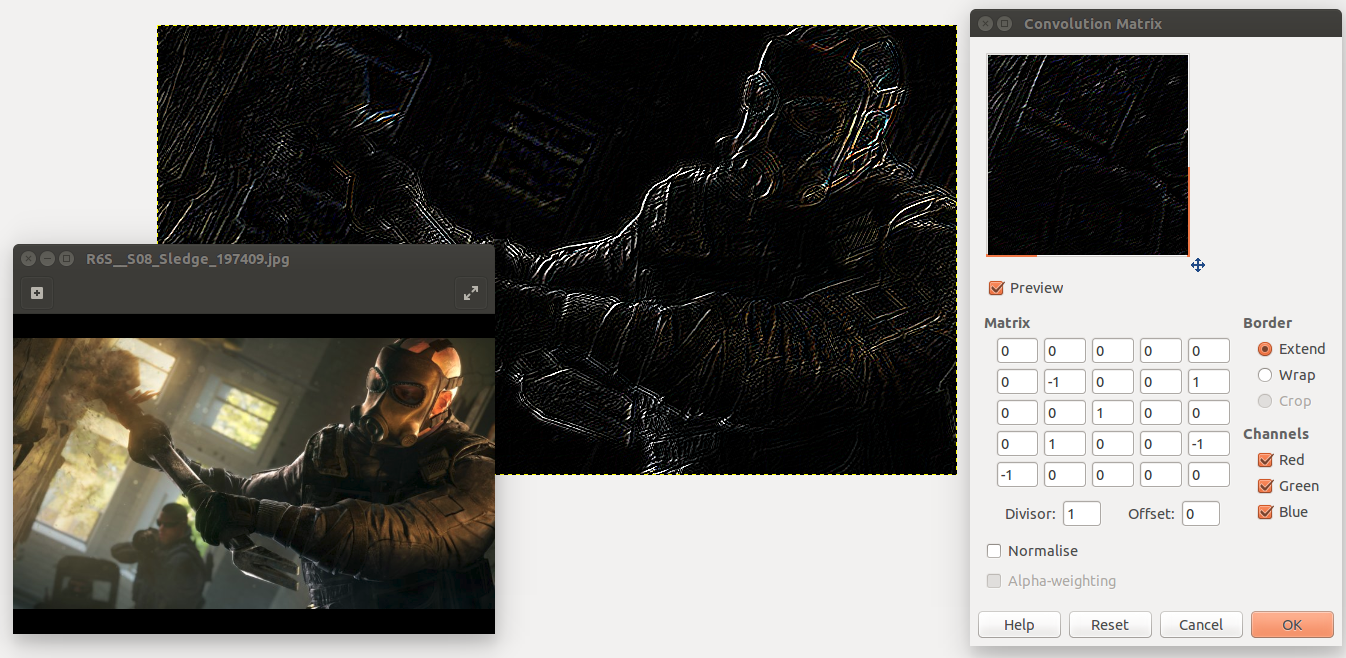
간단히 말해서 이미지의 한 부분이 서로 비슷비슷한 색상을 갖고 있으면 서로 상쇄를 시켜줘서 0값이 되지만, 갑작이 sharp-edge 부분을 만나게 되면은 색상차이가 갑자기 커져서 해당 부분의 convolution값이 높아지게 됩니다. 위의 예제에서처럼 Rainbow Six Siege의 slege의 사진중에 윤곽선만 도드라져 보이는게 보일것입니다. 이러한 이유때문에 저렇게 나오는 것입니다.
What are convolutional Neural Networks?
Convolution의 개념에 대해서 알았다면, CNN 이란 질문이 나올 것 입니다.
CNN은 기본적으로 several layers of convolutions이 결과값에 ReLU, Tanh같은 Nonlinear function을 적용한 것들입니다.
먼저 input image에 convolution을 적용하여 output을 꺼냅니다. 해당 output은 input image의 local connection으로 연결이 되어 있으며,
각각의 layers들은 각기 다른 filters를 적용합니다.
궁극적으로 CNN은 filters의 값들을 자동으로 학습을 합니다. (그게 뭐건간에 내가 다루는 task에 따라서 자동으로)
예를 들어서 Image Classification에서 첫번째 layer에서 edges들을 인식할것입니다.
그뒤 해당 edges들을 사용하여, 간단항 형태(shapes)들을 2번째 layer에서 인식을 하게 됩니다.
그뒤 해당 simple shapes들을 사용하여, 더 높은 형태의 특징들 (예를 들어서 얼굴, 사과, 동전, 자동차 등등..)의 특징들을 인식하게 됩니다.
마지막 layer에서는 더 높은 차원의 특징들을 뽑아내 classification을 하게 됩니다.
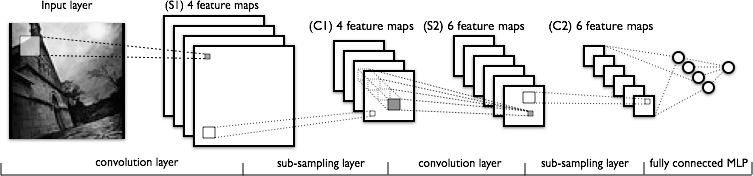
The LeNet Architecture (1990s)
최초의 CNN중의 하나인 LeNet5이 나온 이후 많은 improvements가 나왔습니다.
하지만 모두 핵심적인 아키텍쳐는 동일하며 최초의 LeNet을 이해하면 파생된 알고리즘을 이해하는 것도 어렵지 않습니다.
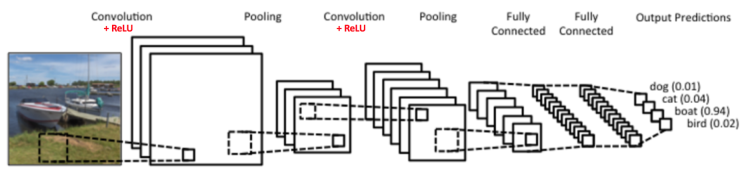
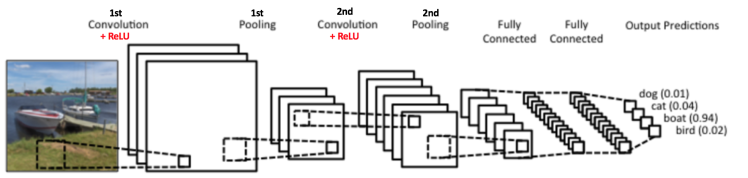
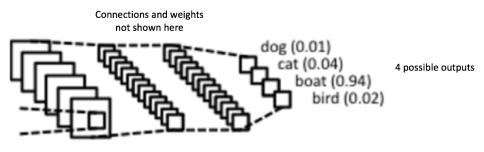
위의 이미지는 ConvNet으로서 원래의 LeNet과 많이 유사하며, 4개의 카테고리 (dog, cat, boat, bird)로 분류합니다.
ConvNet에는 주요 4가지 operations이 있습니다.
- Convolution
- Non Linearity (ReLU)
- Pooling or Sub Sampling
- Classification (Fully Connected Layer)
Filter (Sliding Window, Kernel) -> Feature Map (convolved feature, activation map)

빨간색 Filter 그리고 녹색 Filter 는 서로 다른 feature maps을 내놓습니다.
CNN에서는 Training Process를 통해서 해당 filter들의 값을 학습합니다.
중요 포인트는 filter의 갯수, filter의 크기, network의 아키텍쳐등등 고려해야 할 사항이 많습니다.
Feature Map (Convolved Feature)의 크기는 3개의 parameters에 의해서 결정됩니다.
-
Depth
Depth는 filter의 갯수와 일치합니다. 아래 이미지의 경우 3개의 filter가 존재하고, 즉 3개의 전혀다른 feature maps을 만들어냅니다.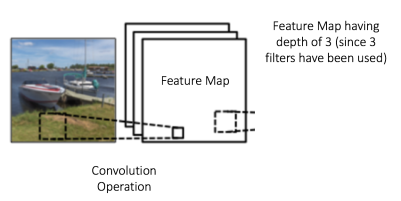
-
Stride
원본 이미지위에서 filter matrix가 움직이면서 feature map을 만드는데.. 이때 한번 움직일때마다 얼만큼씩 움직이는가 하는 값입니다.
예를 들어, stride값이 1 이면, 1픽셀씩 filter를 움직일것이고, stride값이 2이면 filter matrix를 2픽셀 크기만큼 움직일것입니다.
Stride의 값이 클수록 더 작은 feature map을 만들어냅니다. -
Zero-Padding
Input matrix에다가 zeros값의 border를 씌우면 편리한 점이 있습니다. Filter를 적용하여 feature map의 크기를 컨트롤 할 수 있습니다.
Zero padding을 적용하는 것을 Wide Convolution 이라고 하며, 안하는 것을 Narrow Convolution 이라고 합니다.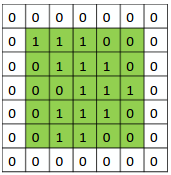
Non Linearity (ReLU)
LeNet 아키텍쳐를 보면, Convolution Operation 마다 ReLU라 불리는 추가적인 operation이 사용되었습니다.
ReLU는 Rectified Linear Unit을 뜻하며, Non-Linear Operation입니다.
파이썬으로 간단히 공식을 쓰면 다음과 같습니다.
relu = lambda x: max(0, x)
relu(13) # 13
relu(0) # 0
relu(-5) # 0 ReLU는 element wise operation (즉 pixel단위로 적용됨)으로서 모든 negative pixel들을 0값으로 바꿔줍니다.
이것을 하는 이유는 ConvNet이 다루는 실질적인 데이터들 대부분이 Non-Linear이고, Convolution은 Linear Operation이기 때문에
ReLU같은 Non-Linear Function을 도입함으로서 Non-Linearity 로 만들어 주는 것입니다.

ReLU외에도 다른 Non-Linear Functions인 tanh 또는 sigmoid등을 사용할수 있습니다만.. CNN에서는 ReLU가 performance가 가장 뛰어납니다.
The Pooling Step
Spatial Pooling (SubSampling 또는 DownSampling으로도 불립니다.)은 각각의 feature map의 dimensionality을 줄이면서 가장 중요한 정보를 유지시킵니다.
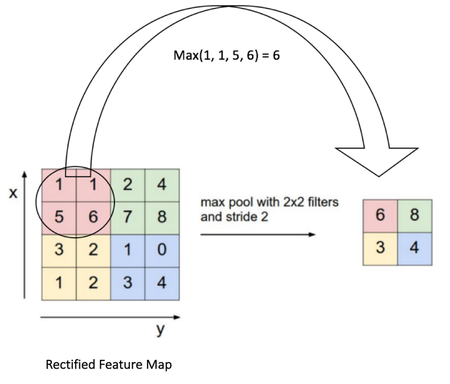
Spatial Pooling은 여러가지 타입이 있습니다. (Max, Average, Sum, etc..)
예를 들어, Max Pooling의 경우 (2*2 window) 가장 큰 값을 rectified feature map으로부터 취합니다.
Average Pooling의 경우 모든 값의 합친값의 평균값을 가져옵니다.
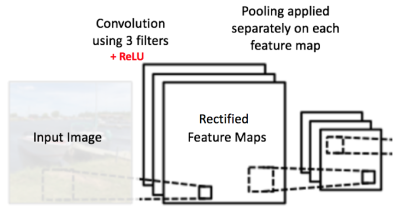
아래 그림에서 보듯이, Pooling은 가각의 feature maps들에 따로따로 적용되기 때문에, 3개의 각기 다른 Pooling output maps을 갖게 됩니다.
Convolution, ReLU, 그리고 Pooling에 대해서 알아보았습니다. 실제로는 아래의 그림처럼 좀 더 복잡한 형태를 갖는 경우가 많습니다.
Fully Connected Layer
해당 부분은 Softmax Activation Function을 사용하는 일반적인 Multi Layer Perceptron입니다. (SoftMax는 0~1사이의 값을 내보냄)
BackPropagation
아래 예제처럼 Boat를 분류하려고 한다면 다음과 같이 데이터를 만들수 있습니다.
- Input Image: Boat
- Target Vector: [0, 0, 1, 0]
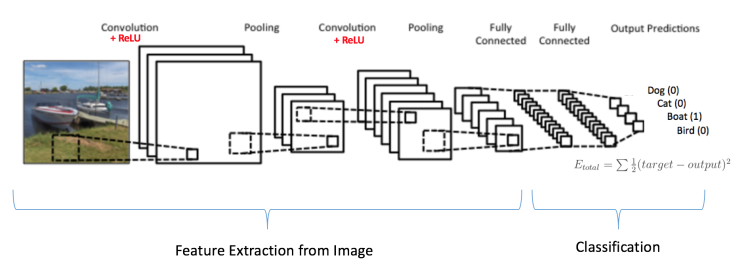
BackPropagation을 통한 training은 다음으로 요약될수 있습니다.
- Pooling Layers는 feature extractor로, fully connected layers는 classifier로 작동합니다.
- Initialization 모든 filters, parameters, weights 를 random values로 초기화 합니다.
- Forward Propagation training image를 받아서, convolution, ReLU, Pooling operations, Fully Connected Layer를 거칩니다.
random으로 초기화가 되어있으니 [0.2, 0.6, 0.1, 0.4] 처럼 결과물이 나올것입니다. - Cost Function 전체 에러률을 계산합니다. (전체 4개의 error값에 대한 총 요약)
\(\sum \frac{1}{2} \cdot ( target\ probability - output\ probability)^2\) - Gradient Descent Network에서 모든 weights값들에 대한 gradient를 계산하고, 모든 filter values, weights, 그리고 parameter values를 업데이트 합니다.
How much deep we need to go?
경우에 따라서 수십개의 Convolutions 그리고 Pooling Layers를 갖기도 합니다.
포인트는 더 많은 convolution steps을 갖을수록, 더 복잡한 features를 인식할수 있게 됩니다.
초기 layers에서는 어떤 선이나 윤곽들을 인식하지만, layer가 상위단으로 갈 수록 얼굴같은 복잡한 형태를 인식하게 됩니다.
아래 그림은 Convolutional Deep Belief Network에서 나온 이미지 입니다.
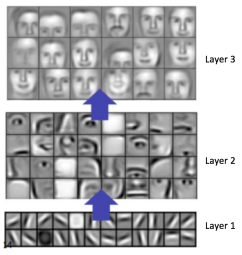
Ohter ConvNet Architectures
- LeNet (1990s)
- AlexNet (2012)
- ZF Net (2013)
- GoogleNet (2014)
- VGGNet (2014)
- ResNets (2015)
- DenseNet (August 2016)